|


 


"The Semantic Web is an extension of the
current web in which information is given
well-defined meaning, better enabling computers and people to work in
cooperation."
Tim Berners-Lee, James Hendler, Ora Lassila,
The Semantic Web, Scientific American, May 2001 .
¿Qué es la Web semántica?
De forma similar a como la presentó
Tim
Berners-Lee en 1998 y adaptando los ejemplos al hipertexto, podemos decir que la World Wide Web, basada en documentos y enlaces de hipertexto, fue diseñada para la
lectura humana y no para que la información que
contiene pudiera procesarse de
forma automática. Si hacemos una búsqueda de
documentos, por ejemplo, por el término "hipertexto", la
Web no distingue entre
los distintos significados o contextos en los que aparece este término
(programas para diseñar hipertexto, información docente, empresas que anuncian
su web, etc.). La Web actual tampoco permite automatizar procesos,
como por ejemplo, buscar un seminario sobre hipertexto, hacer la reserva de
plaza, consultar los medios de transporte disponibles hasta la ciudad donde se
celebre el evento, reservar billete, y conseguir un plano de dicha ciudad. Aun
utilizando un potente buscador, se
pierden muchas horas navegando por los
resultados obtenidos tras la consulta, para acceder a la información de forma manual,
cuando esto lo podría hacer un programa o agente inteligente.
La Web Semántica vendría a ser una
extensión de la Web actual dotada de significado, esto es, un espacio donde la información
tendría un
significado bien definido, de manera que pudiera ser interpretada tanto por
agentes humanos como por agentes computerizados.
La Web Semántica ha sido impulsada por Tim
Berners-Lee, creador de la WWW, y otras personas
relacionados con el
W3C
(World Wide Web Consortium). El primer avance en este sentido, fue la
publicación en septiembre de 1998, por parte de Berners-Lee de 2 documentos
denominados
Semantic
Web Road Map y
What the
Semantic Web can represent.
En el año 2000,
Berners-Lee
ofreció una conferencia en el marco del W3C donde propuso: “La nueva información
debe ser reunida de forma que un buscador pueda "comprender", en lugar de
ponerla simplemente en una "lista”. La Web semántica sería una red de documentos
"más inteligentes" que permitan, a su vez, búsquedas más inteligentes.
La idea sería aumentar la inteligencia
de los contenidos de las páginas web dotándolas de contenido semántico. La Web actual
posee una gran capacidad para
almacenar datos y puede leer y visualizar los contenidos, pero no es
capaz de pensar ni de entender todo lo que contiene. Se precisa, por lo tanto,
un nueva Web -la Web semántica- que hará posible no sólo almacenar los datos,
sino entender e interpretar el sentido de esta información. De esta forma,
Berners-Lee presenta la nueva arquitectura en que se basará la Web Semántica, no
entendida como una nueva Web, sino como una extensión de la Web existente.
En mayo de 2001, Tim Berners Lee, James Hendler y
Ora Lassila popularizan la idea de la Web Semántica al publicar un
artículo en la revista Scientific American titulado "The Semantic Web: a new
form of Web content that is meaninful to computers will unleash a revolution of
new possibilities", donde explican de forma sencilla su idea de la Web
Semántica y los primeros pasos que hay que dar para llevarla a cabo.
Según Berners-Lee, la arquitectura de la Web
Semántica se podría representar de la siguiente forma:
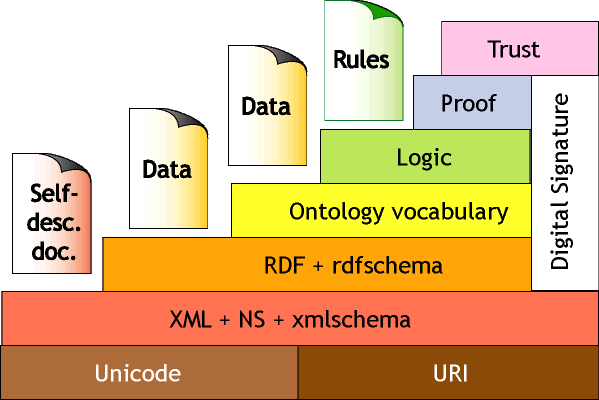
Fuente: Tim Berners-Lee.
Semantic Web -XML2000. Architecture
http://www.w3.org/2000/Talks/1206-xml2k-tbl/slide11-0.html
La mayoría de los sitios web están construidos en lenguaje
HTML con marcas o etiquetas que se muestran cuando se visualiza el código fuente, pero que
permanecen ocultas en la visualización normal de los
navegadores y que
contienen información sobre el contenido de la página, enlaces hacia otras páginas,
formatos de letra, color, párrafos, imágenes,
vídeos, etc. Los orígenes de
la Web se basaron en el carácter abierto y universal de la base de la Web: el
lenguaje HTML, y el empleo de archivos
ASCII y los gráficos GIF y/o JPG. Esto
permite a los buscadores clasificar los documentos HTML de la red y ponerlos en
una página web a modo de índice o catálogo, que se puede mostrar por medio del
navegador. Gracias a que el lenguaje HTML se ajusta a unas normas
estandarizadas, todos los ordenadores pueden reproducir correctamente esos
documentos. Sin embargo, el lenguaje HTML se quedaba corto pues,
orientado a la presentación de datos, la
información que ofrece es muy limitada, no permite describir datos y no es
extensible, esto es, únicamente ofrece un pequeño número de etiquetas. El sistema evolucionó y se realizaron
algunas mejoras para hacer este lenguaje algo más dinámico con la introducción
de otros elementos como DHTML,
Javascript, hojas de estilo
e, incluso, se añadieron a la Web otros lenguajes que permitieran ofrecer una
información más estructurada, como el lenguaje XML, pero hacen falta
otros lenguajes que permitan una descripción más detallada del documento y de
su contenido, y que faciliten la comunicación entre los ordenadores. Y también
hace falta una nueva generación de buscadores más inteligentes que puedan leer
y evaluar rápidamente los documentos de Internet.
Así pues, el desarrollo de la Web semántica requiere la
utilización de otros lenguajes como el lenguaje estructurado XML (Extensible Markup
Language) y el lenguaje RDF (Resource Description Framework) que puedan dotar a cada
página,
a cada archivo y a cada recursos o contenido de la red, de una lógica y un significado, y
que permitan a los
ordenadores conocer el significado de la información que
manejan con el fin de que esta información pueda no sólo ser presentada en
pantalla,
sino también que pueda ser integrada y reutilizada.
XML ha logrado convertirse hoy en un
lenguaje estándar.
Se trata de
un subconjunto del complejo y sofisticado lenguaje SGML que aporta datos
estructurados a la Web y que se ha convertido en la infraestructura preferida
para el intercambio de datos. Además, las páginas XML pueden ubicar
metadatos, esquemas XML y
esquemas
RDF,
que aportan un mecanismo para que los programas puedan interpretar y comprender
documentos con un vocabulario descriptivo.
Para poder explotar la Web semántica, se
necesitan lenguajes semánticos más
potentes, esto es, lenguajes de marcado capaces de representar el conocimiento
basándose en el uso de metadatos y ontologías. Utilizando anotaciones
RDF y RDF Schema se pueden
presentar algunas facetas sobre conceptos de un dominio del conocimiento y se puede,
mediante relaciones taxonómicas, crear una jerarquía de conceptos. Pero se
precisan lenguajes de marcado (basados en RDF) con
una mayor expresividad y capacidad de razonamiento para representar los
conocimientos que contienen las
ontologías. Además, estos lenguajes deben ser
estandarizados y formalizados para que su uso sea universal, reutilizable y
compartido a lo largo y ancho de la Web. Se necesita un lenguaje común basado
en web, con suficiente capacidad expresiva y de razonamiento para
representar la semántica de las ontologías. De esta forma, la utilización de lenguajes
tales como OWL son una paso más en la consecución de la
Web Semántica.
Es necesario, pues, crear
una ontología o biblioteca de vocabularios descriptivos/semánticos, definidos
en formato RDF y ubicados en la Web para determinar el significado contextual de
una palabra por medio de la consulta a la ontología apropiada. De esta forma,
agentes
inteligentes y programas autónomos podrían rastrear la Web de forma automática
y localizar, exclusivamente, las páginas que se refieran a la palabra buscada
con el significado y concepto precisos con el que interpretemos ese término. Por
lo tanto, para potenciar el uso de ontologías
en la Web, se necesitan aplicaciones específicas de búsqueda de
ontologías, que indiquen a los usuarios las
ontologías existentes y sus características para
utilizarlas en su sistema.
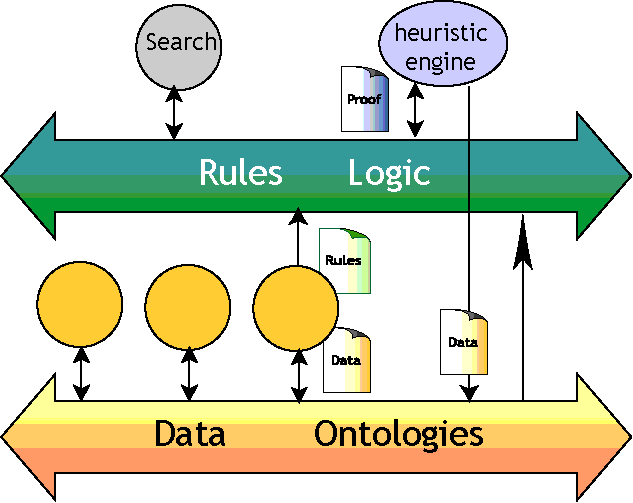
Fuente: Tim Berners-Lee.
Semantic Web -XML2000. Semantic Web Bus.
http://www.w3.org/2000/Talks/1206-xml2k-tbl/slide14-0.html
En este sentido, se entiende por agente inteligente aquella entidad de software
que recoge, filtra y procesa la información contenida en la Web, realiza
inferencias sobre dicha información e interactúa con el entorno sin
necesidad de supervisión o control constante por parte del usuario.
James A. Hendler en su artículo Is there and Intelligente Agent in
Your Future? recoge las cualidades que
debería tener un agente inteligente ideal. Para este autor, un agente debe ser:
-
Comunicativo: el agente debe entender las necesidades,
objetivos y preferencias del usuario, ya que de dicha comunicación o
interacción usuario-agente depende que el agente pueda llevar a cabo su
función de forma eficiente. Asimismo, debe poder comunicarse con el entorno
mediante representaciones compartidas de conocimiento (ontologías).
-
Capaz: el agente debe poder actuar en una
determinada clase de mundo. El agente no sólo debe proporcionar una
información, sino también un servicio, es decir, debe tener capacidad para
hacer cosas. Por ejemplo, si se precisa un artículo de revista y ésta es de
pago, el agente debe ser capaz de encontrar el artículo, informar del precio,
dar el número de tarjeta de crédito, etc.
-
Autónomo: el agente, además de comunicarse, debe poder
interactuar con el entorno, tomando decisiones y actuando por sí solo,
limitando sus acciones según el nivel de autonomía permitida por el usuario.
-
Adaptable: el agente debe ser capaz de aprender del
entorno: usuarios (preferencias), fuentes de información y otros agentes, etc.
El papel del agente inteligente en el proceso de recuperación
"semántica" de información no debe confundirse con el de un
buscador
inteligente. Un buscador inteligente se aprovechará del enriquecimiento
semántico de los recursos web para mejorar (principalmente en la precisión) la
recuperación de información, aunque su funcionamiento se basará, como los
actuales buscadores, en la previa indización de todos aquellos recursos
susceptibles de ser recuperados. En cambio, un agente inteligente recorrerá la
Web a través de los enlaces entre recursos (hiperdocumentos,
ontologías, ...) en
busca de aquella información que le sea solicitada, pudiendo además
interactuar
con el entorno para el cumplimiento de tareas encomendadas. Por ejemplo, un
agente inteligente, ante una consulta dada, podría consultar autónomamente un
buscador, y a partir de sus resultados, explorar la Web hasta encontrar la
información solicitada, pudiendo finalmente llevar a cabo una acción sobre dicho
recurso, como podría ser la reserva de una plaza en un Seminario, de un vuelo,
y/ o de una habitación en un hotel. Según P. Raghaban,
las necesidades de información de un usuario cuando acude a los buscadores son
las siguiente:
-
informacional: aprender o saber acerca de algo
(~40%). Por ejemplo: hemoglobina baja.
-
navegacional: ir a determinada página (~25%). Por
ejemplo: United Airlines.
-
transaccional: hacer algo por medio de la Web
(~35%):
-
acceder a un servicio. Por ejemplo: Mendocino weather.
-
descargar algo (downloads). Por ejemplo: imágenes
de la superficie de Marte.
-
comprar. Por ejemplo: Nikon Coopix.
-
Áreas grises:
La Web Semántica debería ser capaz de procesar contenido,
razonarlo y hacer deducciones lógicas a partir de éste, y realizar, cuando un
usuario quiera delegar ciertas tareas en el software,
todas estas acciones de forma automática.
Un agente inteligente entiende (lo que se pide), comprende (el contenido de los
sitios), valida (si lo encontrado corresponde a lo pedido) y deduce (nueva
información sobre la ya obtenida). Pero, para entender una consulta, comprender
sitios web, validar información y deducir nueva información se precisa
estandarizar : :
Y éstas son, precisamente, las funciones que aportan las
distintas capas de la Web Semántica.
-
Unicode: el alfabeto. Se trata de una
codificación del texto que permite utilizar los símbolos de diferentes idiomas
sin que aparezcan caracteres extraños. De esta forma, se puede expresar
información en la Web Semántica en cualquier idioma.
-
URI: las referencias.
URI es el acrónimo de "Uniform Resource
Identifier" o Identificador Uniforme de Recursos, identificador único que permite
la localización de un recurso que puede ser accedido vía Internet. Se trata
del URL (descripción de la ubicación) más el
URN (descripción del espacio de
nombre).
-
XML
+
NS + xmlschema:
se trata de la capa más técnica de la Web Semántica. En esta capa se agrupan
las diferentes tecnologías que hacen posible que los agentes puedan entenderse
entre ellos. XML ofrece un formato común para intercambio de documentos, NL (namespaces)
sirve para cualificar elementos y atributos de nombres usados en XML
asociándolos con los espacios de nombre identificados por referencias URI y
XML Schema ofrece una plantilla para elaborar
documentos estándar. De esta forma, aunque se utilicen diferentes fuentes, se
crean documentos uniformes en un formato común y no propietario.
-
RDF +
rdfschema: basada y apoyada
en la capa anterior, esta capa define el
lenguaje universal con el cual podemos expresar diferentes ideas en la
Web Semántica. RDF es un lenguaje simple mediante el cual definimos sentencias
en el formato de una 3-upla o triple (sujeto: el recurso al que nos referimos;
predicado: el recurso que indica qué es lo que estamos definiendo; y objeto:
puede ser el recurso o un literal que podría considerarse el valor de lo que
acabamos de definir). El modelo RDF o Resource Description Framework es un
modelo común (Framework) que permite hacer afirmaciones sobre los recursos (Description)
y que hace posible que estos recursos pueden ser nombrados por URIs (Resource).
Por su parte RDF Schema provee un vocabulario definido sobre RDF que permite
el modelo de objetos con una semántica claramente definida. Esta capa no sólo
ofrece descripción de los datos, sino también cierta información semántica.
Tanto esta capa como la anterior corresponden a las anotaciones de la
información (metadatos).
-
Lenguaje de Ontologías: ofrece un criterio para
catalogar y clasificar la información. El uso de ontologías permite describir
objetos y sus relaciones con otros objetos ya que una ontología es la
especificación formal de una conceptualización de un dominio concreto del
conocimiento. Esta capa permite extender la funcionalidad de la Web Semántica,
agregando nuevas clases y propiedades para describir los recursos.
-
Lógica: además de ontologías se precisan
también reglas
de inferencia. Una ontología puede expresar la regla "Si un código de ciudad
está asociado a un código de estado, y si una dirección es el código de ciudad,
entonces esa dirección tiene el código de estado asociado". De esta forma, un
programa podría deducir que una dirección de la Universidad Complutense, al
estar en la ciudad de Madrid, debe estar situada en España, y debería por lo
tanto estar formateado según los estándares españoles. El ordenador no
"entiende" nada de lo que está procesando, pero puede manipular los términos de
modo mucho mas eficiente beneficiando la inteligibilidad humana.
-
Pruebas: será necesario el intercambio de
"pruebas" escritas en el lenguaje unificador (se trata del lenguaje que hace
posible las inferencias lógicas hecha posibles a través del uso de reglas de
inferencia tal como es especificado por las ontologías) de la Web Semántica.
-
Confianza: los agentes deberían ser muy
escépticos acerca de lo que leen en la Web Semántica hasta que hayan podido
comprobar de forma exhaustiva las fuentes de información. (Web Of Trust RDF
Ontology -WOT-
http://xmlns.com/wot/0.1/ y FOAF
http://xmlns.com/foaf/0.1/))
-
Firma digital: bloque encriptado de datos que
serán utilizados por los ordenadores y los agentes para verificar que la
información adjunta ha sido ofrecida por una fuente específica confiable. (XML
Signature WG:
http://www.w3.org/Signature/)
En suma, el objetivo de la Web Semántica es que la Web pase
de ser una colección
de documentos a convertirse en una base de conocimiento.
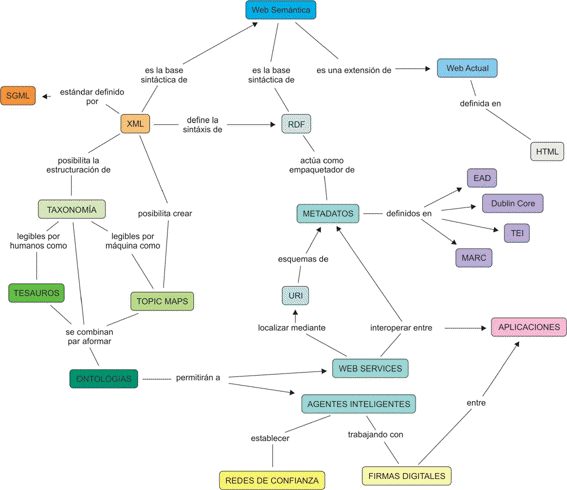
Fuente: Mapa conceptual de la Web Semántica.
Keilyn Rodríguez Perojo y Rodrigo Ronda León.
"Web Semántica: un nuevo enfoque
para la organización y recuperación de información en la web".
Acimed,
vol. 13, núm. 6, November-December 2005.
http://bvs.sld.cu/revistas/aci/vol13_6_05/aci030605.htm
La principal fuente de información sobre la Web
Semántica es el W3 Consortium,
una de cuyas actividades actuales es desarrollar y estandarizar un marco común
que permita compartir y reutilizar datos entre distintas aplicaciones y
plataformas para hacer posible la Web Semántica. Todas las
actividades en relación a la Web Semántica se reflejan en la página: http://www.w3.org/2001/sw
Aquí se recogen los estándares más significativos para su
desarrollo, que incluyen los lenguajes RDF y OWL, numerosos artículos y
presentaciones, así como los grupos de trabajo
creados para desarrollarla.
Existe una Oficina Española del W3C
http://www.w3c.es/ que
ofrece documentación y recursos sobre la Web Semántica en castellano. En ella
podemos acceder a las siguientes Guías introductorias:
Ya existen muchos proyectos que han puesto en marcha
aplicaciones para el desarrollo de la Web Semántica. He aquí un ejemplo de
navegador semántico desarrollado dentro
del proyecto Haystack del
MIT, que personaliza la navegación según los intereses y gustos del
usuario. Entre las funciones de esta navegador podemos
destacar las siguientes: importa archivos RDF/XML de la Web o archivos del
sistema, navega por las páginas web y los recursos semánticos, crea colecciones
de recursos de la Web Semántica y permite navegar por ellos, lee weblogs basados
en RSS, permite el etiquetado de cualquier objeto, maneja colecciones de
fotos digitales y organiza archivos de música, monta la información en
mini-portales, desarrolla ontologías a medida, etc.

Fuente:
http://haystack.lcs.mit.edu/staging/eclipse-download.html
También contamos con algunos buscadores para la Web
Semántica, que realizan las búsquedas sobre
ontologías y lenguajes semánticos tales como
RDF y
OWL. El más conocido es
SWoogle: Semantic Web Search
http://swoogle.umbc.edu/
desarrollado por la Universidad de Maryland (Baltimore, USA).
Se trata de un buscador que busca
ontologías
(tiene indizadas más de 10.000), documentos y términos escritos tanto en
RDF como OWL, esto es, busca
documentos de la Web Semántica o Semantic Web Documents (SWDs).
Curiosamente, tanto su propio nombre como su
interfaz de
presentación son muy similares a los de
Google.

Fuente: SWoogle
http://swoogle.umbc.edu/
Pero también encontramos otros buscadores semánticos como
Semantic Web Search:
http://www.semanticwebsearch.com/ un motor de búsqueda que
localiza tanto vocabularios como recursos basados en
vocabularios RDF, RSS, FOAF,
DOAP, calendarios y otras
aplicaciones RDF, o
CORESE,
un proyecto del INRIA (Institut
National de Recherche en Informatique et en Automatique)
que se enfoca a visualizar la Web Semántica puesto que se basa en gráficos
conceptuales:
http://www-sop.inria.fr/acacia/corese
Pero para que la Web Semántica sea una realidad, precisa
tanto de un lenguaje de consulta estándar y de un protocolo de recuperación. Con
este fin, el W3C ha desarrollado los siguientes lenguajes:
Aunque también existen otros lenguajes de consulta e inferencia como
Triple,
un lenguaje RDF para la transformación hacia la Web Semántica (http://triple.semanticweb.org/)
o RQL
(RDF Query Language) y
eRQL (easy RDF Query Language), ambos lenguajes de interrogación
semántica para consultar esquemas e instancias RDF.
Y siguen existiendo proyectos basados en lenguajes que sirven para representar
el conocimiento como
LOOM
(http://www.isi.edu/isd/LOOM/LOOM-HOME.html)
un lenguaje y entorno para construir aplicaciones inteligentes y que se basa en
un sistema de representación que se utiliza para ofrecer un soporte deductivo y que permite hacer
definiciones y establecer reglas, clasificar y
consultar conocimiento, o
CLIPS -
C Language Integrated Production System- (http://www.ghg.net/clips/WhatIsCLIPS.html)
que ofrece una herramienta para gestionar una extensa variedad de
conocimiento con el soporte de tres paradigmas de programación diferentes:
basado en reglas, orientado a objetos y procesal.
También son continuos los desarrollos del lenguaje OWL para el desarrollo de la
Web Semántica y los
Servicios Web. De esta forma, se ha
desarrollado el
WSML (Web
Service Modeling Language)
http://www.wsmo.org/wsml/wsml-syntax o
Lenguaje de Modelado de Servicios Web basado en
WSMO (Web Service Modelling Ontology
http://www.wsmo.org
y
http://www.w3.org/Submission/WSMO/).
WSML consta de una variedad de lenguajes llamados: WSML-Core, WSML-DL,
WSML-Flight,
SWRL (Semantic Web
Rules Language http://www.w3.org/Submission/SWRL/)
y WSML-Full. Una descripción completa de todos ellos pueden encontrarse en la:
WSML Specification
http://www.wsmo.org/TR/d16/d16.1/v0.21/#part:variants)
y también existe el protocolo
UDDI (The Universal Description, Discovery and Integration (UDDI)
http://www.uddi.org/
para llevar a cabo los Servicios Web.
Los proyectos más importantes en el campo de la Web Semántica son los
siguientes:
 AKT
(Advanced Knowledge Technologies): el consorcio AKT
agrupa 5 universidades del Reino Unido y fue fundado por el
Engineering and Physical
Sciences Research Council (EPSRC). Su fin es ayudar a desarrollar la próxima
generación de tecnologías del conocimiento para dar soporte a la gestión del
conocimiento de las organizaciones. AKT pretende desarrollar y extender métodos
integrados y servicios para capturar, modelar, publicar, reutilizar, compartir y
gestionar el conocimiento. Para ello se tienen en cuenta los recientes
desarrollos en inteligencia artificial, psicología, lingüística, multimedia y
tecnologías de Internet.
http://www.aktors.org/akt/ AKT
(Advanced Knowledge Technologies): el consorcio AKT
agrupa 5 universidades del Reino Unido y fue fundado por el
Engineering and Physical
Sciences Research Council (EPSRC). Su fin es ayudar a desarrollar la próxima
generación de tecnologías del conocimiento para dar soporte a la gestión del
conocimiento de las organizaciones. AKT pretende desarrollar y extender métodos
integrados y servicios para capturar, modelar, publicar, reutilizar, compartir y
gestionar el conocimiento. Para ello se tienen en cuenta los recientes
desarrollos en inteligencia artificial, psicología, lingüística, multimedia y
tecnologías de Internet.
http://www.aktors.org/akt/
 ASG
(Adaptive Services Grid): es un proyecto integrado dentro del
6º Programa
Marco de la Comisión Europea. El proyecto que comenzó en septiembre
de 2004 y dura 2 años, agrupa 22 participantes de 7 países. El objetivo es
desarrollar un prototipo de plataforma abierta para la innovación, creación,
composición y lanzamiento de servicios. ASG cuenta con las principales
organizaciones de producción científica y tecnológica que hacen uso del
conocimiento y con las instituciones europeas líderes en la investigación
y desarrollo del software, las telecomunicaciones y la industria telemática.
http://asg-platform.org/cgi-bin/twiki/view/Public/WebHome ASG
(Adaptive Services Grid): es un proyecto integrado dentro del
6º Programa
Marco de la Comisión Europea. El proyecto que comenzó en septiembre
de 2004 y dura 2 años, agrupa 22 participantes de 7 países. El objetivo es
desarrollar un prototipo de plataforma abierta para la innovación, creación,
composición y lanzamiento de servicios. ASG cuenta con las principales
organizaciones de producción científica y tecnológica que hacen uso del
conocimiento y con las instituciones europeas líderes en la investigación
y desarrollo del software, las telecomunicaciones y la industria telemática.
http://asg-platform.org/cgi-bin/twiki/view/Public/WebHome
 DBin: es una nueva clase de aplicación web: un P2P Web Semántico con una
filosofía para
"compartir archivos" y/o un Cliente de
Grupos de noticias semántico.
Similar a un cliente para compartir archivos,
DBin conecta directamente a otros peers. Instead of files, sin embargo, éste
bajará "información relevante" sobre los temas que se especifiquen. De
forma más técnica, permite compartir y recibir "información estructurada
semánticamente" usando RDF y otros componentes de la Web Semántica.
http://www.dbin.org/
DBin: es una nueva clase de aplicación web: un P2P Web Semántico con una
filosofía para
"compartir archivos" y/o un Cliente de
Grupos de noticias semántico.
Similar a un cliente para compartir archivos,
DBin conecta directamente a otros peers. Instead of files, sin embargo, éste
bajará "información relevante" sobre los temas que se especifiquen. De
forma más técnica, permite compartir y recibir "información estructurada
semánticamente" usando RDF y otros componentes de la Web Semántica.
http://www.dbin.org/
 DIP
(Data, Information, and Process
Integration with Semantic Web Services): el objetivo de DIP es desarrollar y
extender la Web Semántica y las tecnologías de los Servicios Web para producir
una nueva infraestructura tecnológica para los Servicios de la Web Semántica.
http://dip.semanticweb.org/ DIP
(Data, Information, and Process
Integration with Semantic Web Services): el objetivo de DIP es desarrollar y
extender la Web Semántica y las tecnologías de los Servicios Web para producir
una nueva infraestructura tecnológica para los Servicios de la Web Semántica.
http://dip.semanticweb.org/
 ELeGI (The
European Learning Grid Infraestructure): Una red semántica para el
aprendizaje humano para la puesta en marcha de escenarios futuros de aprendizaje
basado en la ubicuidad y la colaboración, y centrados en la experiencia y el
aprendizaje contextualizado a través del diseño, implementación y validación del
aprendizaje en red.
http://www.elegi.org/ ELeGI (The
European Learning Grid Infraestructure): Una red semántica para el
aprendizaje humano para la puesta en marcha de escenarios futuros de aprendizaje
basado en la ubicuidad y la colaboración, y centrados en la experiencia y el
aprendizaje contextualizado a través del diseño, implementación y validación del
aprendizaje en red.
http://www.elegi.org/
 Esperonto Project:
es un proyecto que fue desarrollado entre 2002 y 2005 dentro del 5º Programa
Marco de la Comisión Europea y cuyo objetivo era hacer de
puente entre la Web actual y la Web Semántica. La descripción del proyecto
y los resultados se pueden encontrar en:
http://esperonto.semanticweb.org/ Esperonto Project:
es un proyecto que fue desarrollado entre 2002 y 2005 dentro del 5º Programa
Marco de la Comisión Europea y cuyo objetivo era hacer de
puente entre la Web actual y la Web Semántica. La descripción del proyecto
y los resultados se pueden encontrar en:
http://esperonto.semanticweb.org/
ESWS. European Semantic Web Symposium: el primero de estos simposios se celebró en Creta
en el año 2004. Estos encuentros tienen como fin mostrar las tecnologías,
desarrollos y aplicaciones de la Web Semántica a nivel europeo y mundial.
http://www.esws.org
 KW (Knowledge Web):
es una Red de Excelencia FP6 que ayuda a dar soporte de
transición a las tecnologías de ontologías desde el sector académico a la
industria. El consorcio actual está integrado por 18 participantes que incluyen
líderes en Web Semántica, multimedia, tecnologías del lenguaje humano, agentes,
etc. http://knowledgeweb.semanticweb.org/ KW (Knowledge Web):
es una Red de Excelencia FP6 que ayuda a dar soporte de
transición a las tecnologías de ontologías desde el sector académico a la
industria. El consorcio actual está integrado por 18 participantes que incluyen
líderes en Web Semántica, multimedia, tecnologías del lenguaje humano, agentes,
etc. http://knowledgeweb.semanticweb.org/
 IMS Global:
se trata de un consorcio en el que participan más de 50 organizaciones y
empresas, que tiene como objetivo el aprendizaje
global a través de la Web. En este marco, se trabaja con esquemas XML y documentación
estructurada en donde RDF juega un papel fundamental, por ejemplo en la definición de
vocabularios y taxonomías.
http://www.imsglobal.org IMS Global:
se trata de un consorcio en el que participan más de 50 organizaciones y
empresas, que tiene como objetivo el aprendizaje
global a través de la Web. En este marco, se trabaja con esquemas XML y documentación
estructurada en donde RDF juega un papel fundamental, por ejemplo en la definición de
vocabularios y taxonomías.
http://www.imsglobal.org
 NeOn: proyecto fundado por la Comisión Europea dentro
del 6º Programa Marco.
Coordinado por la Open University. En el proyecto también participan
instituciones líderes de Europa en el área del modelado del conocimiento y las
ontologías. El fin de NeOn es crear el primer servicio orientado de
infraestructura abierta y metodología asociada para soportar el desarrollo de
aplicaciones de la Web Semántica, con el objetivo de extender el estado de la
cuestión a soluciones viables económicamente. Estas aplicaciones se realizarán
sobre una red de ontologías contextualizadas, mostradas localmente que no
necesariamente tengan una consistencia global. El proyecto NeOn es impulsado por
diferentes sectores como el farmacéutico, el de la agricultura y pesca, que
utilizan un amplio volumen de conjuntos de datos que no se pueden gestionar
utilizando las tecnologías actuales.
http://www.neon-project.org/
NeOn: proyecto fundado por la Comisión Europea dentro
del 6º Programa Marco.
Coordinado por la Open University. En el proyecto también participan
instituciones líderes de Europa en el área del modelado del conocimiento y las
ontologías. El fin de NeOn es crear el primer servicio orientado de
infraestructura abierta y metodología asociada para soportar el desarrollo de
aplicaciones de la Web Semántica, con el objetivo de extender el estado de la
cuestión a soluciones viables económicamente. Estas aplicaciones se realizarán
sobre una red de ontologías contextualizadas, mostradas localmente que no
necesariamente tengan una consistencia global. El proyecto NeOn es impulsado por
diferentes sectores como el farmacéutico, el de la agricultura y pesca, que
utilizan un amplio volumen de conjuntos de datos que no se pueden gestionar
utilizando las tecnologías actuales.
http://www.neon-project.org/
 OpenKnowledge:
tiene por objetivo crear una nueva forma de abrir y compartir arquitecturas de
conocimiento de forma coordinada poniendo el foco de atención en la semántica
para la interacción y uso en las comunidades web. "Open" en OpenKnowledge se
emplea en 2 sentidos: como un sistema abierto en el cuál cualquiera puede
utilizarlo en cualquier momento; y en el sentido de abierto para ser ensamblado,
logrado por medio de la participación con un coste individual bajo.
http://www.openk.org/ OpenKnowledge:
tiene por objetivo crear una nueva forma de abrir y compartir arquitecturas de
conocimiento de forma coordinada poniendo el foco de atención en la semántica
para la interacción y uso en las comunidades web. "Open" en OpenKnowledge se
emplea en 2 sentidos: como un sistema abierto en el cuál cualquiera puede
utilizarlo en cualquier momento; y en el sentido de abierto para ser ensamblado,
logrado por medio de la participación con un coste individual bajo.
http://www.openk.org/
 ESSI
(European Semantic System Initiative): es la suma de dos proyectos SDK Project Cluster
y ASG: El SDK (SEKT, DIP, Knowledge Web) Cluster se ha unido
estratégicamente con ASG (Adaptive Services Grid). Este nuevo ESSI Cluster
combina los Servicios de la Web Semántica y las soluciones basados en sistemas
semánticamente potentes con arquitecturas orientadas a servicios semánticos. ASG
añadirá valor al nuevo ESSI cluster porque provee un prototipo conceptual
de plataforma abierta para adaptar los servicios a las innovaciones, creación,
composición y publicación. ESSI es un cluster de 4 grandes proyectos
europeos en el área de la Web Semántica y de los Servicios de la Web Semántica
conocidos como: SEKT, DIP, Knowledge Web y ASG. Mediante la cooperación de estos
proyectos, se pretende fortalecer la investigación y la industria europeas por
medio de la estandarización a nivel mundial. Cada proyecto se especializa en un
aspecto concreto de la Web Semántica, como construir la infraestructura,
desarrollar y explotar las tecnologías del conocimiento basadas en la Web
Semántica, enriquecer los Servicios Web con metadatos semánticos y soportar el
proceso de transición de las tecnologías de ontologías desde el mundo académico
a la industria.
http://www.sdk-cluster.org/ ESSI
(European Semantic System Initiative): es la suma de dos proyectos SDK Project Cluster
y ASG: El SDK (SEKT, DIP, Knowledge Web) Cluster se ha unido
estratégicamente con ASG (Adaptive Services Grid). Este nuevo ESSI Cluster
combina los Servicios de la Web Semántica y las soluciones basados en sistemas
semánticamente potentes con arquitecturas orientadas a servicios semánticos. ASG
añadirá valor al nuevo ESSI cluster porque provee un prototipo conceptual
de plataforma abierta para adaptar los servicios a las innovaciones, creación,
composición y publicación. ESSI es un cluster de 4 grandes proyectos
europeos en el área de la Web Semántica y de los Servicios de la Web Semántica
conocidos como: SEKT, DIP, Knowledge Web y ASG. Mediante la cooperación de estos
proyectos, se pretende fortalecer la investigación y la industria europeas por
medio de la estandarización a nivel mundial. Cada proyecto se especializa en un
aspecto concreto de la Web Semántica, como construir la infraestructura,
desarrollar y explotar las tecnologías del conocimiento basadas en la Web
Semántica, enriquecer los Servicios Web con metadatos semánticos y soportar el
proceso de transición de las tecnologías de ontologías desde el mundo académico
a la industria.
http://www.sdk-cluster.org/
 SEKT Project (Semantically -Enabled
Knowledge Technologies): co-fundado por el
6º Programa Marco de
la UE parar llevar a cabo la Sociedad del Conocimiento. La visión de SEKT es
desarrollar y explotar las tecnologías del conocimiento bajo unos nuevos
parámetros de gestión donde se rompan las fronteras entre gestión de documentos,
gestión del contenido y y gestión del conocimiento, y donde la gestión del
conocimiento se convierta en una actividad cotidiana sin gran esfuerzo. El
conocimiento se ofrece de forma automática al usuario por medio de una gama de
dispositivos. La estrategia del SEKT se basa en la sinergia de los conocimiento
técnicos de varios centros de excelencia en las tecnologías de ontologías y
metadatos, la innovación y las tecnología del lenguaje humano, con las grandes
empresas que lideran el mercado. http://www.sekt-project.com/ SEKT Project (Semantically -Enabled
Knowledge Technologies): co-fundado por el
6º Programa Marco de
la UE parar llevar a cabo la Sociedad del Conocimiento. La visión de SEKT es
desarrollar y explotar las tecnologías del conocimiento bajo unos nuevos
parámetros de gestión donde se rompan las fronteras entre gestión de documentos,
gestión del contenido y y gestión del conocimiento, y donde la gestión del
conocimiento se convierta en una actividad cotidiana sin gran esfuerzo. El
conocimiento se ofrece de forma automática al usuario por medio de una gama de
dispositivos. La estrategia del SEKT se basa en la sinergia de los conocimiento
técnicos de varios centros de excelencia en las tecnologías de ontologías y
metadatos, la innovación y las tecnología del lenguaje humano, con las grandes
empresas que lideran el mercado. http://www.sekt-project.com/
Así pues, los proyectos en marcha son numerosos y
variados. Una lista más exhaustiva de proyectos se ofrece en
Recursos sobre la Web Semántica.
Y también existen numerosos proyectos a pequeña escala que han dado lugar a proyectos web concretos que aplican los
principios de la Web Semántica, he aquí algunos ejemplos:
-
Confoto: es un servicio de navegación, etiquetado
multilingüe y reutilización de fotos, conferencias y descripciones de personas.
Combina categorización RDF con la sindicación de contenidos y el uso de
herramientas interactivas de edición e interfaces de intercambio y consulta de
datos usando SPARQL.
http://www.confoto.org/home
-
Personal Reader : ofrece un marco para desarrollar y
mantener lectores de contenido web.
http://www.personal-reader.de/
Sin embargo, la Web Semántica
no goza de excesiva popularidad entre los creadores de sedes web debido a que no está pensada para seres humanos, sino para agentes o programas
que recorran la World Wide Web e infieran nuevos datos. En los aspectos técnicos ha habido
grandes logros ya que existen librerías para lenguajes como
Java, PHP,
Perl,
Python, etc; y también existen distintos
instrumentos para inferir
información como Jena,
CWM,
EARL, etc. pero la
realidad es que existen muy pocos agentes
que humanicen la información de la Web Semántica.
Los avances en el campo semántico han sido notables, pero no
tan espectaculares como se auguraba en los primeros tiempos del desarrollo de la
inteligencia artificial y los sistemas expertos y como algunos autores predicen
que ocurrirá en un futuro. Llevando hasta el extremo la idea de la Web Semántica
como una base global de conocimientos, han surgido nuevas iniciativas que van más
allá de este concepto y que equiparan el funcionamiento de la Web al
funcionamiento de un cerebro global, de la misma forma que
Peter Russell
en 1983 propuso la idea de un cerebro global que pudiera emerger de una red
mundial de seres humanos conectados por las telecomunicaciones. (Ver
vídeo http://www.peterussell.com/GB/GBVideo.html)
Fuente: http://pespmc1.vub.ac.be/SUPORGLI.html
Así, ciertos autores han la abundado en
la concepción de esta red global del conocimiento:
Francis Heylighen,
Cliff Joslyn y
Johan Bollen hablan de la futura Web como algo que piensa y
aprende, como un superorganismo social que tiene un cerebro global.

Fuente: La Web inteligente. II
Jornada de en.red.ando. Barcelona, 26-10-2001.
A pesar de este tecno-optimismo, también existen numerosos
críticos que aducen que este tipo de planteamientos son no sólo descabellados
sino, incluso, temibles. La realidad es que todavía estamos muy lejos de
conseguir, incluso, algunos de los planteamientos menos complejos de la Web Semántica. En los
años 70, el desarrollo de la inteligencia artificial condujo a cierta euforia
que el tiempo transcurrido y los escasos avances alcanzados se han encargado de
desmentir. Lo que sí es cierto, es que hay muchas líneas de
trabajo abiertas en relación con la Web Semántica, líneas que tienen que ver con
los lenguajes semánticos y lenguajes de definición de
ontologías, metodologías de desarrollo e
integración de ontologías y otros vocabularios de dominios concretos del
conocimiento, agentes, tecnologías y
servicios web, etc. y que muchas empresas y
grupos de investigación trabajan en este sentido.
Pero la realidad es que, actualmente, la construcción y recuperación de
estructuras semánticas no se puede llevar a cabo de forma automática.
En los albores de la Web nadie pensó en etiquetar categorías y añadir
metadatos,
pues la mayor parte del contenido de la Web estaba diseñado para leer, no para
que fuera manipulado por ordenadores,
robots y agentes.
Pronto se vio que, ante las colosales dimensiones de la
Web y la heterogénea información que contenía era
necesario no sólo organizar la información, sino también clasificarla y
categorizarla con el fin
de poder realizar búsquedas y recuperar la información de forma automática. Y
esto sólo es posible mediante una indización y
clasificación previas, esto es, con la generación de
documentos previamente estructurados formal y semánticamente, y utilizando un
lenguaje que sea independiente de la plataforma o aplicación empleadas. En el mundo analógico e impreso
la descripción, indización y clasificación de documentos ha sido un coto vedado para
bibliotecarios y profesionales de la documentación, una de cuyas tareas
habituales era la elaboración de
tesauros y ontologías
para describir, categorizar y clasificar la información. Esta labor se vio
pronto invadida, en el mundo digital, por informáticos, matemáticos, ingenieros
del conocimiento, lingüistas, expertos en inteligencia artificial, arquitectos
de la información, etc. que son los que han tomado la delantera en las técnicas
de descripción, búsqueda,
recuperación y acceso a la World Wide Web.
Los "documentalistas robotizados" no tiene por qué comprender la información,
sólo precisan de metadatos y
ontologías para indizar y
clasificar los documentos
o recursos de la Web. Los lenguajes de marcado actuales han añadido capacidades
semánticas a las capacidades de estructuración formal de los datos. Los
documentos web se codifican mediante lenguajes de metadatos y
ontologías,
lenguajes semánticos que
aportan representaciones compartidas de conocimiento en forma de conceptos
relacionados y reglas de inferencia lógicas, estos documentalistas inteligentes
podrán asistir a los usuarios tanto en la
recuperación de información como en
otro tipo de servicios. De esta forma, los agentes "no humanos" cobran una
especial relevancia como actores principales en la futura World Wide Web, esto
es, la Web Semántica, y se convierten, al igual que los usuarios humanos, en un
nuevo tipo de usuario capaz de extraer información y de interactuar con el
entorno. Otro aspecto a desarrollar es la nueva interacción que se estable entre
estos usuarios computerizados y los usuarios humanos.
Así pues, la Web Semántica cuenta ya con una nutrida infraestructura de lenguajes y
tecnologías para hacerla posible. La sintaxis se basa en el lenguaje XML y
derivados, y la semántica en los lenguajes RDF (S) y
OWL, y también
están presentes otras muchas aplicaciones y tecnologías ya desarrolladas como
URIs, Topic Maps,
XFML, firmas digitales, etc.
y numerosas empresas y centros de investigación están trabajando en ella. Sin embargo, para que la antigua tarea humana e intelectual de la
identificación, indización y clasificación de documentos pueda hacerse mediante
ordenadores sólo podrá llevarse a la práctica si colaboran de forma
interdisciplinar documentalistas, lingüistas, informáticos, arquitectos de la
información, ingenieros y expertos en inteligencia artificial, etc.
Bibliografía
 ANTONIOU, Grigorius. HARMELEN, Frank Van. A Semantic Web Primer.
http://www.ics.forth.gr/isl/swprimer/
ANTONIOU, Grigorius. HARMELEN, Frank Van. A Semantic Web Primer.
http://www.ics.forth.gr/isl/swprimer/
BERNERS-LEE, Tim. Semantic Web - XML2000. Slides
http://www.w3.org/2000/Talks/1206-xml2k-tbl [Volver]
BERNERS-LEE, Tim. What the Semantic Web can represent.
September, 1998.
http://www.w3.org/DesignIssues/RDFnot.html
BERNERS-LEE, Tim. MILLER, Eric. "The Semantic Web lifts off". ERCIM News No. 51, October 2002. Special Semantic Web.
http://www.ercim.org/publication/Ercim_News/enw51/
y
 http://www.ercim.org/publication/Ercim_News/enw51/EN51.pdf
http://www.ercim.org/publication/Ercim_News/enw51/EN51.pdf
BERNERS-LEE, Tim. Semantic Web Road Map. September, 1998.
http://www.w3.org/DesignIssues/Semantic.html
BERNERS-LEE, Tim. HENDLER, James. LASSILA, Ora. "The Semantic Web".
Scientific American, May 2001.
http://www.sciam.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21&pageNumber=1&catID=2
CASTAÑEDA, Javier. La Web inteligente. Baquía, 15-11-2001.
http://www.baquia.com/noticias.php?id=9116
Consortium. org "The future of the Web".
Consortium Standard Bulletin, june, 2005, vol. IV, No. 6.
http://www.consortiuminfo.org/bulletins/jun05.php
http://www.consortiuminfo.org/bulletins/pdf/jun05.pdf
Controlled Vocabulary. com
http://controlledvocabulary.com
DAML. The DARPA Agent Markup Language Homepage.
http://www.daml.org/
DIENG-KUNTZ, Rose. "Corporate Semantic Webs". ERCIM News No. 51, October 2002. Special Semantic Web.
http://www.ercim.org/publication/Ercim_News/enw51/
http://www.ercim.org/publication/Ercim_News/enw51/EN51.pdf
DUMBILL, Edd. XMLWatch: Tracking provenance of RDF data.
http://www-106.ibm.com/developerworks/xml/library/x-rdfprov.html
 Fundación Sidar. Web Semántica Hoy.
http://www.wshoy.sidar.org/
Fundación Sidar. Web Semántica Hoy.
http://www.wshoy.sidar.org/
GILCHRIST, Alan. From
Aristotle to the ‘semantic web’.
http://www.la-hq.org.uk/directory/record/r200201/article2.html
GUTIÉRREZ, Claudio. La Web Semántica.
http://www.dcc.uchile.cl/~cgutierr/websemantica/websemantica.pdf
HASSAN MONTERO, Yusef. MARTÍN FERNÁNDEZ, Francisco Jesús. Web Semántica: El
papel del Arquitecto de la Información.
http://www.nosolousabilidad.com/articulos/web_semantica.htm
HENDLER, James. "Is there and Intelligente Agent in
Your Future?" Nature, 11 March 1999.
http://www.nature.com/nature/webmatters/agents/agents.html
[Volver]
HENDLER, James. "Agents and the Semantic Web". IEEE, March/April 2001
Vol. 16, No. 2.
http://doi.ieeecomputersociety.org/10.1109/5254.920597
HENDLER, James. BERNERS-LEE, Tim. MILLER, Eric. "Integrating
Applications on the Semantic Web", Journal of the Institute of
Electricarl Engineers of Japan, Vol 122(10), October, 2002.
http://www.w3.org/2002/07/swint
HERRERA, Álvaro. Annotea.
http://www.tejedoresdelweb.com/307/article-5817.html
IMS Global Learning Consulting.
http://www.imsglobal.org/
INKEL. ¿Qué es la web semántica?
http://f14web.com.ar/inkel/que-es-la-web-semantica
International Journal of Knowledge and Learning (IJKL).
http://www.inderscience.com/ijkl/
International Journal of Learning and Change (IJLC).
http://www.inderscience.com/ijlc/
International Journal of Metadata, Semantics and
Ontologies (IJMSO).
http://www.inderscience.com/ijmso/
International Journal on Semantic Web and
Information Systems (IJSWIS).
http://www.idea-group.com/journals/details.asp?id=4625)
ISWC 2003 2nd International Semantic Web Conference
http://iswc2003.semanticweb.org/
ISWC 2002
1 International Semantic Web Conference
http://iswc2002.semanticweb.org/
SWWS-1st
SWWS-1
International Semantic Web Working Symposium (SWWS)
http://www.semanticweb.org/SWWS/
ISWC2004.
3rd International Semantic Web Conference.
http://iswc2004.semanticweb.org/
Journal of Web Semantics.
http://www.websemanticsjournal.org
KAHAN, Jose (W3C). Semantic Web Implementation Experiences with Annotea
and Amaya.
http://www.w3.org/2004/Talks/1306-jk-swade/Overview.html
Knowledge Media Institute KMI. Projects.
http://kmi.open.ac.uk/projects/
Knowledge Web
http://knowledgeweb.semanticweb.org/
KOIVUNEN,
Marja-Riitta. MILLER, Enric. W3C Semantic Web Activity.
http://www.w3.org/2001/12/semweb-fin/w3csw
 LÓPEZ LEANDRO, Mariano.
¿Qué es la Web Semántica?
http://f14web.com.ar/inkel/que-es-la-web-semantica
LÓPEZ LEANDRO, Mariano.
¿Qué es la Web Semántica?
http://f14web.com.ar/inkel/que-es-la-web-semantica
MAEDCHE, Alexander. STAAB , Steffen. STOJANOVIC, Nenad.
STUDER, Rudi. SURE, York.
SEmantic Portal: The SEAL approach.
http://www.aifb.uni-karlsruhe.de/WBS/sst/Research/Publications/semanticportal.pdf
MARTELI, SIGNORE. "Semantic Characterisation of Links and
Documents". ERCIM News No. 51, October 2002. Special Semantic Web.
http://www.ercim.org/publication/Ercim_News/enw51/ y
http://www.ercim.org/publication/Ercim_News/enw51/EN51.pdf
MARTÍN, María de los Ángeles. Búsqueda y navegación semántica.
http://www.w3.org/2001/sw/Europe/reports/dev_workshop_report_8/maria/Overview.html
McCATHIENEVILE, Charles (W3C). Introducción a la Web Semántica.
http://www.w3.org/2001/sw/Europe/talks/040613-cmn/all
MÉNDEZ, EVA. "La Web semántica, una web 'más bibliotecaria'". Boletín de
la SEDIC, nº 41, 2004.
http://www.sedic.es/p_boletinclip41_confirma.htm
Mindswap Homepage. http://www.mindswap.org/
Multimedia and the Semantic Web. 2nd European Semantic Web Conference,
Heraklion, Crete, 29 May to 1 June.
http://www.acemedia.org/ESWC2005_MSW/
Ontoweb.org
http://www.ontoweb.org
OpenRDF.org
http://www.openrdf.org/
PAN, Jeff. HORROCKS, Ian. Metamodeling
Architecture of Web Ontology Languages. In Proceeding of the Semantic
Web Working Symposium (SWWS), Stanford, USA, 2001.
http://www.cs.man.ac.uk/~horrocks/Publications/download/2001/rdfsfa.pdf
PEASE, Adam. Why Use DAML?
http://www.daml.org/2002/04/why.html
PEIS REDONDO, Eduardo et al. Ontologías, metadatos y agentes:
recuperación "semántica" de la información.
http://www.nosolousabilidad.com/hassan/jotri2003.pdf
 PÉREZ AGÜERA, José Ramón. Automatización de Tesauros y
su utilización en la Web Semántica.
http://www.bib.uc3m.es/~mendez/swad-13Jn/tati.ppt PÉREZ AGÜERA, José Ramón. Automatización de Tesauros y
su utilización en la Web Semántica.
http://www.bib.uc3m.es/~mendez/swad-13Jn/tati.ppt
RAGHAVAN, Prabhakar. Challenges in the Web Search.
htttp://www.ciw.cl/material/raghavan2005.pdf
[Volver]
Rewerse. Rewerse: Reasoning on the Web with Rules and Semantics. http://rewerse.net/
RODRÍGUEZ PEROJO, Keilyn. RONDA LEÓN, Rodrigo.
"Web Semántica: un nuevo enfoque para la organización y recuperación de
información en la web. Acimed, vol. 13, núm. 6, November-December 2005.
http://bvs.sld.cu/revistas/aci/vol13_6_05/aci030605.htm
Semanticscripting.org
http://www.semanticscripting.org/
SemanticWeb.org
http://www.semanticweb.org/
SemanticWeb.
http://groups.yahoo.com/group/semanticweb (Lista de distribución).
"Semantic Web and IS". ECIS 2005,
Regensburg.
http://www.ecis2005.de/semantic.html
"Special Semantic Web". ERCIM News No. 51, October 2002.
http://www.ercim.org/publication/Ercim_News/enw51/ También en .pdf
http://www.ercim.org/publication/Ercim_News/enw51/EN51.pdf
"Special Issue on Semantic Web
and Social Networks". SISGEMIS Bulletin, Vol. 2, (3&4) 2005.
http://www.sigsemis.org/newsletter/december2005/vol2-issue34.pdf
SWED. Semantic Web Environmental Directory.
http://www.swed.org.uk/swed/
SWoogle: Semantic Web Search.
http://swoogle.umbc.edu/
SIGSEMIS. Association for Information Systems SIG on
Semantic
Web and Information Systems.
http://www.sigsemis.org
SIGSEMIS Bulletin.
http://www.sigsemis.org/newsletter/
Useful Information Company. DOAP: Description of a project.
http://usefulinc.com/doap/
VV.
AA. "El cerebro global".
Pliegos de opinión. Revista
digital. Número 1, Primavera 2002, Jerez.
http://www.pliegosdeopinion.net/pdo1/Dossier/marco1.htm
W3C. "Introducción al uso de la Web Semántica".
Taller SWAD-Europe
13 Junio 2004, Madrid,
 España.
http://www.w3.org/2001/sw/Europe/events/200406-esp/ España.
http://www.w3.org/2001/sw/Europe/events/200406-esp/
W3C. Guía breve de Web Semántica.
http://www.w3c.es/divulgacion/guiasbreves/WebSemantica
W3C.
SPARQL Protocol for RDF.http://www.w3.org/TR/rdf-sparql-protocol/
W3C.
SPARQL Query Language for RDF.
http://www.w3.org/TR/rdf-sparql-query/
W3C.
Web Ontology Language (OWL) Use Cases and
Requirements, W3C Recommendation.
http://www.w3.org/TR/webont-req/
W3C.
OWL Web Ontology Language Reference, W3C Recommendation.
http://www.w3.org/TR/owl-ref/
W3C.
OWL Web Ontology Language Semantics and Abstract Syntax, W3C
Recommendation.
http://www.w3.org/TR/owl-absyn/
W3C.
OWL Web Ontology Language Overview, W3C Recommendation.
http://www.w3.org/TR/owl-features/
W3C.
OWL Web Ontology Language Test Cases, W3C Recommendation.
http://www.w3.org/TR/owl-test/
W3C.
OWL Web Ontology Language Guide, W3C Recommendation.
http://www.w3.org/TR/owl-guide/
W3C.
Semantic Web Activity.
http://www.w3.org/2001/sw/
W3C. Resource Description
Framework (RDF). http://www.w3.org/RDF/
WALKER, Adrian. "Lightweight English Heavyweight Inference and a Semantic
Distance Measure". NIST/NSF Semantic Distance Workshop, November,
2003.
http://www.reengineeringllc.com/Internet_Business_Logic_and_Semantic_Web_Presentation.pdf
WILSON
http://www.w3c.rl.ac.uk/pasttalks/BNCOD_MDW.pdf

Servicios Web
Recursos sobre Web Semántica
La Web 2.0
|