|


 


Los procesos de estandarización y normalización llevados a
cabo en el mundo del documento impreso tanto en lo referente a la
identificación, descripción y acceso al documento, se han mostrado claramente insuficientes
para que estos modelos puedan ser trasladados al universo del documento
hipertextual sin sufrir modificación alguna y sin tener en cuenta las
características propias del nuevo medio. Identificar los nuevos recursos
digitales
para su estructuración,
acceso y referencia es un proceso que entraña muchas más dificultades de las
que se le suponen al texto impreso.
Existen problemas concretos derivados de la especificidad de los
nuevos recursos digitales como son la inestabilidad y volatilidad tanto del
contenido como de la localización del documento; problemas relacionados con la
cantidad, puesto que el número de documentos crece exponencialmente y parece
imposible identificar y clasificar la masa ingente de información que aumenta
día a día. A esto se une, que la proliferación de documentos en la red, se
desarrolla sin ningún criterio concreto de estructuración de la información.
Hay distintos tipos de información y en diferentes
morfologías (texto,
imagen, sonido,
vídeo, bases de datos, software...), en diferentes
lenguas, con diferentes formatos (htm, html, txt,
zip, pdf, gif, wav, midi, avi, etc.), y sobre los temas más variados
(información científica, comercial, meramente informativa, personal, etc.) y
se plantean problemas a la hora de aislar una unidad documental. También
existen dudas en cuanto a la descripción de los contenidos, puesto que estos
cambian constantemente. Por otro lado, existen problemas relacionados con la
ubicación del documento ya que un documento electrónico puede estar
distribuido en cualquier parte de la red mundial, puede
localizarse en varios sitios a la vez, se puede acceder a él desde distintos
protocolos (www; ftp; telnet; gopher, etc.), puede mudar de dirección e, incluso,
puede desaparecer definitivamente sin previo aviso.
Todos estos problemas y especificidades de los documentos
digitales, han conducido a que exista un interés creciente por parte de
documentalistas y científicos de la información, hacia la normalización y
estandarización en te, aquellos que agrupamos bajo el concepto
de documentación, los que mejor se adapten a la normalización
(documentos técnicos y científicos, libros, artículos y publicaciones en
línea, informes administrativos, material
didáctico de todo tipo, patentes, etc.), pero también existe un creciente
interés por parte de la industria y las empresas en normalizar los documentos
en los cuales anuncian sus productos o los que utilizan para las transacciones
comerciales.
Analizaremos a continuación las iniciativas que se han tomado,
en materia de normalización, tanto para la localización e identificación de
documentos electrónicos, como
para la descripción formal (catalogación y citación de recursos
electrónicos) y para la descripción de contenidos (metadatos). Hay que destacar el importante papel que, en la normalización,
juegan instituciones como la International
Standarization Organization (ISO), el
American
National Standards
Institute ANSI/NISO y la International
Federation of Library Associations (IFLA) o incluso la
Biblioteca del Congreso de Estados
Unidos en lo referente a la
estandarización de normas bibliográficas y documentales (normas ISO, ISBDs,
Formato MARC, etc.); y a organismos como el Consorcio
World Wide Web (W3C) o la Internet
Engineering Task Force (IETF), la rama de ingeniería y
protocolos de
Internet, en la estandarización y desarrollo de Internet.
Recientemente, el W3C ha establecido una Recomendación para
fijar la arquitectura de la World Wide Web. Se trata de
Architecture of the World Wide Web, Volume One:
http://www.w3.org/TR/webarch/
En esta recomendación se da una
importancia primordial a los identificadores, que, junto con los protocolos y
formatos constituirían dicha arquitectura en la que se basa la Web. La siguiente
imagen muestra las relaciones entre identificador, recurso y representación.
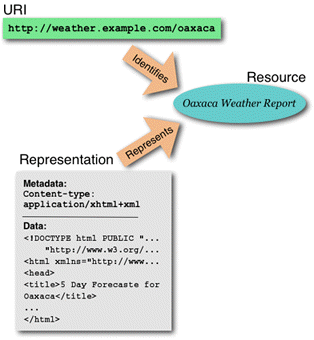
Fuente: W3C Architecture of the World Wide
Web.
http://www.w3.org/TR/webarch/
Bibliografía:
 GARCÍA CAMARERO, Ernesto. GARCÍA
MELERO, Luis Ángel. La Biblioteca digital. Madrid,
Arco/Libros, 2001. GARCÍA CAMARERO, Ernesto. GARCÍA
MELERO, Luis Ángel. La Biblioteca digital. Madrid,
Arco/Libros, 2001.
 IETF
Home Page.
http://www.ietf.org/ IETF
Home Page.
http://www.ietf.org/
IFLA
Home Page. http://www.ifla.org/
ISO Home
Page. http://www.iso.org
The Library of Congress Home Page.
http://www.loc.gov/
Lista
de Distribución NORMAWEB.
http://listas.bcl.jcyl.es/normaweb/
MÉNDEZ
RODRÍGUEZ, Eva. MERLO VEGA, José Antonio. "
Localización, identificación y descripción de documentos web: tentativas hacia
la normalización". Jornadas Españolas de Documentación (7. 2000. Bilbao). La
gestión del conocimiento: retos y soluciones de los profesionales de la
información. Bilbao: Universidad del País Vasco, FESABID, 2000.
http://exlibris.usal.es/merlo/escritos/bilbao2.htm
 http://exlibris.usal.es/merlo/escritos/pdf/bilbao2.pdf
http://exlibris.usal.es/merlo/escritos/pdf/bilbao2.pdf
MÉNDEZ RODRÍGUEZ ,
E.M. Metadatos y recuperación de la
información: estándares, problemas y aplicabibilidad en bibliotecas digitales.
Gijón, Trea, 2002.
SORLI
ROJO, Ángela. MERLO VEGA, José Antonio. "
El uso de metainformación en los webs de las bibliotecas españolas. Jornadas
Españolas de Documentación (7. 2000. Bilbao). La gestión del conocimiento: retos
y soluciones de los profesionales de la información. Bilbao: Universidad del
País Vasco, FESABID, 2000.
http://exlibris.usal.es/merlo/escritos/bilbao1.htm y
http://exlibris.usal.es/merlo/escritos/pdf/bilbao1.pdf
W3C. Architecture of the World Wide Web, Volume One.
http://www.w3.org/TR/webarch/

Normalización en la localización e identificación
Normalización en la descripción formal
Normalización en la descripción de contenidos
|




