|


 


Uno de los objetivos fundamentales de un sistema de
información es contar no 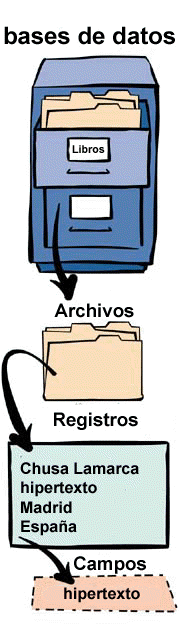 sólo
con recursos de información, sino también con los mecanismos necesarios para
poder encontrar y recuperar estos recursos. De esta forma, las bases de datos se
han convertido en un elemento indispensable no sólo para el funcionamiento de
los grandes
motores de
búsqueda y la recuperación de información a lo largo y ancho de la
Web, sino también para la creación de sedes web, Intranets
y otros sistemas de información en los que se precisa manejar grandes o pequeños
volúmenes de información. La creación de una base de datos a la que puedan
acudir los usuarios para hacer consultas y acceder a la información que les
interese es, pues, una herramienta imprescindible de cualquier sistema
informativo sea en red o fuera de ella. sólo
con recursos de información, sino también con los mecanismos necesarios para
poder encontrar y recuperar estos recursos. De esta forma, las bases de datos se
han convertido en un elemento indispensable no sólo para el funcionamiento de
los grandes
motores de
búsqueda y la recuperación de información a lo largo y ancho de la
Web, sino también para la creación de sedes web, Intranets
y otros sistemas de información en los que se precisa manejar grandes o pequeños
volúmenes de información. La creación de una base de datos a la que puedan
acudir los usuarios para hacer consultas y acceder a la información que les
interese es, pues, una herramienta imprescindible de cualquier sistema
informativo sea en red o fuera de ella.
Una base de datos es una colección de datos organizados y estructurados según un
determinado modelo de información que refleja no sólo los datos en sí
mismos,
sino también las relaciones que existen entre ellos. Una base de datos se diseña
con un propósito especifico y debe ser organizada con una lógica coherente. Los datos
podrán ser
compartidos por distintos usuarios y aplicaciones, pero deben conservar su
integridad y seguridad al margen de las interacciones de ambos. La definición y
descripción de los datos han de ser únicas para minimizar la redundancia y
maximizar la independencia en su utilización.
En una base de datos, las
entidades y atributos del mundo real, se convierten en registros y campos. Estas
entidades pueden ser tanto objetos materiales como libros o fotografías, pero
también personas e, incluso, conceptos e ideas abstractas. Las entidades poseen
atributos y mantienen relaciones entre ellas.
Los modelos clásicos de
tratamiento de los datos son:
-
jerárquico:
puede
representar dos tipos de relaciones entre los datos: relaciones de uno a uno y
relaciones de uno a muchos. Este modelo tiene forma de árbol invertido en el que
una rama puede tener varios hijos, pero cada hijo sólo puede tener un padre.
-
en
red:
Este modelo permite la representación de muchos a muchos, de tal forma que
cualquier registro dentro de la base de datos puede tener varias ocurrencias
superiores a él. El modelo de red evita redundancia en la información, a través
de la incorporación de un tipo de registro denominado el conector. En el modelo
en red se representa el mundo real mediante registros lógicos que representan a
una entidad y que se relacionan entre sí por medio de flechas
-
relacional:.
Desde los años 80 es el modelo más utilizado, ya que permite una mayor eficacia,
flexibilidad y confianza en el tratamiento de los datos. La mayor parte de las
bases de datos y sistemas de información actuales se basan en el modelo
relacional ya que ofrece numerosas ventajas sobre los 2 modelos anteriores, como
es el rápido aprendizaje por parte de usuarios que no tienen conocimientos
profundos sobre sistemas de bases de dados. En el modelo relacional se
representa el mundo real mediante tablas relacionadas entre sí por columnas
comunes. Las
bases de datos que pertenecen a esta categoría se basan en el modelo relaciones,
cuya estructura principal es la relación, es decir una tabla bidimensional
compuesta por líneas y columnas. Cada línea, que en terminología relacional se
llama tupla, representa una entidad que nosotros queremos memorizar en la base
de datos. las características de cada entidad están definidas por las columnas
de las relaciones, que se llaman atributos. Entidades con características
comunes, es decir descritas por el mismo conjunto de atributos, formarán parte
de la misma relación.
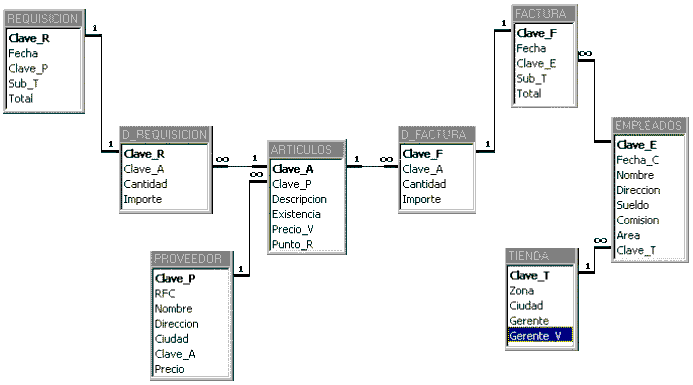
Ejemplo de base de datos relacional
elaborada con Microsoft Access
Hoy también destaca la utilización de
bases de datos distribuidas ya que cada vez es más corriente el uso de
arquitecturas de cliente-servidor y trabajo en grupo. Los principales problemas
que se generan por el uso de la tecnología de bases de datos distribuidas se
refieren a la duplicidad de datos y a su integridad al momento de realizar
actualizaciones a los mismos. Además, el control de la información puede
constituir una desventaja, debido a que se encuentra diseminada en diferentes
localizaciones geográficas.
Recientemente han hecho su aparición los modelos de bases de
datos orientadas a objetos. En estos, el esquema de la base de datos está
representada por un conjunto de clases que definen las características y el
comportamiento de los objetos que conformarán la base de datos.
La diferencia principal respecto a los modelos
anteriores es la no positividad de los datos. Esto es, con una base de datos
tradicional, las operaciones que se tienen que efectuar en los datos se les
piden a las aplicaciones que los usan. Con una base de datos orientada a objetos
sucede lo contrario, los objetos memorizados en la base de datos contienen tanto
los datos como las operaciones posibles con tales datos. En cierto sentido, se
podrá pensar en los objetos como en datos a los que se les ha dotado de "cierta inteligencia" que les permite saber cómo comportarse, sin tener que
apoyarse en aplicaciones externas.
La arquitectura de un sistema de base de datos se basa en 3
niveles distintos:
-
nivel físico:
es el nivel más bajo de
abstracción y el nivel real de los datos almacenados. Este nivel define cómo se
almacenan los datos en el soporte físico, ya sea en registros o de cualquier
otra forma, así como los métodos de acceso. Este nivel lleva asociada una
representación de los datos, que es lo que denominamos Esquema Físico.
-
nivel conceptual:
es el correspondiente a
una visión de la base de datos desde el punto de visto del mundo real. Es decir
se trata con la entidad u objeto representado, sin importar como está
representado o almacenado éste. Es la representación de los datos realizada por
la organización, que recoge los datos parciales de los requerimientos de los
diferentes usuarios y aplicaciones parciales. Incluye la definición de los datos
y las relaciones entre ellos. Este nivel lleva asociado un Esquema Conceptual.
-
nivel de visión:
son partes del esquema
conceptual. El nivel conceptual presenta toda la base de datos, mientras que los
usuarios, por lo general, sólo tienen acceso a pequeñas parcelas de ésta. El
nivel visión es el encargado de dividir estas parcelas. Un ejemplo sería el caso
del empleado de una organización que tiene acceso a la visión de su nómina, pero
no a la de sus compañeros. El esquema asociado a éste nivel es el Esquema de
Visión.
Otros autores utilizan la
denominación de nivel interno, nivel conceptual y nivel externo, para referirse
a estos mismos niveles:
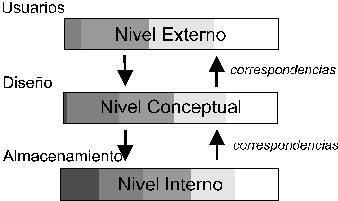
Niveles de la arquitectura de
un sistema de base de datos
Este modelo de arquitectura permite establecer el principio de independencia de
los datos, ya se trate de una independencia lógica o física. La
independencia lógica significa que los cambios en el esquema lógico no deben
afectar a los esquemas externos que no utilicen los datos modificados; la
independencia física significa que el esquema lógico no se va a ver afectado por
los cambios realizados en el esquema interno, correspondientes a modos de
acceso, etc.
A la hora de diseñar una
base de datos hay que distinguir por un lado el modelo de datos (instrumento) y
por otro lado el esquema de datos (el resultado de aplicar ese modelo).
Un modelo de datos es un
conjunto de conceptos, reglas y convenciones que nos permiten describir los
datos del universo del discurso. Un esquema es la estructura de datos obtenida
tras aplicar dicho modelo.
El
modelo de datos es una cuestión fundamental a la hora de diseñar bases de datos.
Jesús Tramullas en Los sistemas de bases de datos recoge estos 3 modelos
fundamentales:
-
Modelos lógicos basados en objetos: los dos más
extendidos son el modelo entidad-relación y el orientado a objetos. El modelo
entidad-relación (E-R) se basa en una percepción del mundo compuesta por
objetos, llamados entidades, y relaciones entre ellos. Las entidades se
diferencian unas de otras a través de atributos. El orientado a objetos también
se basa en objetos, los cuales contienen valores y métodos, entendidos como órdenes
que actúan sobre los valores, en niveles de anidamiento. Los objetos se agrupan
en clases, relacionándose mediante el envío de mensajes. Algunos autores
definen estos modelos como "modelos semánticos".
-
Modelos lógicos basados en registros: el más extendido
es el relacional, mientras que los otros dos existentes, jerárquico y de red,
se encuentran en retroceso. Estos modelos se usan para especificar la estructura
lógica global de la base de datos, estructurada en registros de formato fijo de
varios tipos. El modelo relacional representa los datos y sus relaciones
mediante tablas bidimensionales, que contienen datos tomados de los dominios
correspondientes. El modelo de red está formado por colecciones de registros,
relacionados mediante punteros o ligas en grafos arbitrarios. el modelo jerárquico
es similar al de red, pero los registros se organizan como colecciones de árboles.
Algunos autores definen estos modelos como "modelos de datos clásicos".
-
Modelos físicos de datos: muy poco usados, son el modelo
unificador y el de memoria de elementos. Algunos autores definen estos modelos
como "modelos de datos primitivos".
Los objetivos del modelo de datos son , por un
lado formalizar y definir las estructuras permitidas para representar los datos,
y por otro, diseñar la base de datos.
En el diseño de una base de datos, hay que tener en cuenta
distintas consideraciones, entre las que destacan:
-
la velocidad de acceso
-
el tamaño de la información
-
el tipo de información
-
la facilidad de acceso a la
información
-
la facilidad para extraer la
información requerida
-
el comportamiento del sistema de
gestión de bases de datos con cada tipo de información.
Para plasmar los
tres niveles en el enfoque o modelo de datos seleccionado, es necesario un
programa o
aplicación que actúe como interfaz entre el usuario, los modelos y el sistema físico.
Esta es la función que desempeñan los Sistemas de Gestión de Bases de Datos. Un
Sistema de Gestión de Bases de Datos, también llamado
DBMS (Data Base Management System) no es más que un paquete de software, que se ejecuta en un
ordenador anfitrión (host) que es quien centraliza los accesos a los datos y
actúa de
interfaz entre los datos físicos y los usuarios. Este sistema es capaz de llevar
a cabo funciones como la creación y gestión de la base de datos misma, el
control de accesos y la manipulación de datos de acuerdo a las necesidades de
cada usuario. Así
pues, las bases de datos pueden ser
creadas, mantenidas y gestionadas por una serie de aplicaciones denominadas
Sistemas de Gestión de Bases de Datos (SGBD). De esta forma, cualquier usuario
puede crear una base de datos siguiendo unos parámetros normalizados que
permiten que pueda ser consultada por otros usuarios. Un sistema de gestión de
base de datos está formado por personas, máquinas, programas y datos. Estos
sistemas de gestión abarcan el conjunto de rutinas de software
interrelacionadas cada una de las cuales es responsable de una determinada
tarea.
Jesús Tramullas recoge los
componentes con los que debe contar un sistema de gestión de bases de datos ideal:
-
Un lenguaje de definición de esquema conceptual.
-
Un sistema de diccionario de datos.
-
Un lenguaje de especificación de paquetes de
entrada/salida.
-
Un lenguaje de definición de esquemas de base de datos.
-
Una estructura simétrica de almacenamiento de datos.
-
Un módulo de transformación lógica a física.
-
Un subsistema de privacidad de propósito general.
-
Un subsistema de integridad de propósito general
-
Un subsistema de reserva y recuperación de propósito
general.
-
Un generador de programas de aplicación.
-
Un generador de programas de informes.
-
Un lenguaje de consulta de propósito general.
Los SGBD tienen dos
funciones principales que son:
Además, los SGBD deben incorporar como herramienta fundamental dos
tipos de lenguajes: uno para la definición de los datos, y otro para la manipulación de los
mismos. El
primero se denomina DLL (Data Definition Language) y es el que provee de los medios necesarios
para definir los datos con precisión, especificando las distintas estructuras.
El segundo se conoce como DML (Data Manipulation/Management Language) y es el facilita a los
usuarios el acceso y manipulación de los datos.
Antes de la existencia de las
bases de datos, los ordenadores trabajaban en lo que se conoce como "Sistemas
de procesamiento de Archivos" en los que se guardaban los datos para ser
procesados por programas escritos especialmente para cada clase de
archivo;
esto conducía a un sistema monolítico y de difícil mantenimiento con una
serie de inconvenientes como la dificultad de acceso a ciertos datos de
información, el aislamiento de datos, la falta de integridad, los problemas de
atomicidad en las operaciones, los problemas de acceso concurrente, la falta
de seguridad, etc. Para resolver estos problemas se desarrollaron los Sistemas
de Gestión de Bases de Datos cuyas características hacen al sistema mucho más
eficiente que los sistemas de procesamiento de archivos. Algunas
de estas mejoras se basan en la existencia de una sola copia de los
datos para que todos los programas trabajen con ella, lo que se denominado
obtención de redundancia mínima, para de esta manera poder eliminar la
inconsistencia de los datos; o la capacidad de interactuar en un ambiente
cliente/servidor donde los clientes o usuarios (ya sea en una intranet o
desde Internet) puedan trabajar con un un conjunto único de datos alojados en
un servidor y donde varios clientes podrían estar trabajando al mismo tiempo.
Estas son sólo algunas de las características con que cuenta el modelo de base
de datos relacional y existen diversos motores de base de datos que permiten
trabajar ya sea con bases de datos existentes o creando nuevas con todas las
capacidades de trabajo en red. Numerosas empresas se han volcado al desarrollo
de sistemas de gestión de bases de datos como
Oracle,
Informix,
PostgreSQL,
Sybase,
Microsoft, etc.
y existen tanto soluciones comerciales de pago, como soluciones de acceso
libre. Los principales sistemas gestores de bases de datos se relacionan
aquí. En el diseño de una base de
datos, el tamaño de la misma es una cuestión fundamental,
puesto que éste afecta tanto a la eficiencia en el almacenamiento, como a la
agilidad en la búsqueda y recuperación. Como los datos pueden estar en cualquier
morfología (texto, imagen, audio, etc.), en algunos casos se deberán utilizar
técnicas de compresión de datos con el fin de disminuir el espacio y tamaño de
la base, pero estas técnicas de compresión deberán ir acompañadas de las
correspondientes técnicas de indización que hagan
posible la recuperación de dichos datos. Tradicionalmente se ha hecho una distinción clara entre 2
tipos de bases de datos:
-
Bases de datos referenciales: aquellas
bases de datos que ofrecen
registros que a su vez son representaciones de documentos primarios, y entre
las que cabe distinguir:
-
bibliográficas: aquellas cuyo contenido son registros de
tipo bibliográfico.
-
directorios: aquellas cuyo contenido está referido a la
descripción de otros recursos de información, como por ejemplo un
directorio de bases de datos.
-
Bases de datos fuente: son las que
ofrecen el documento completo, no una representación del mismo, y entre las
que cabe distinguir:
-
numéricas: contienen información de tipo
numérico.
-
textuales: contienen el texto completo de un documento.
-
mixtas: combinan ambos tipos de información.
Sin embargo, el
desarrollo de las aplicaciones multimedia ha dado un vuelco al concepto
tradicional de base de datos, que sólo integraba elementos de información
textual y numérica. Con el multimedia, han hecho su aparición otro tipo de objetos: gráficos, sonoros
y audiovisuales que comparten el mismo entorno que los datos textuales y
numéricos. La aparición del CD-ROM y otros
soportes ópticos como el
DVD con gran capacidad
de almacenamiento de datos y alta velocidad de lectura, han hecho posible el
desarrollo de las bases de datos multimedia. A la vez, se han ido estandarizando
poco a poco los formatos de archivo
gráficos, de audio y de
vídeo, y se han
perfeccionado los métodos de compresión de este tipo de datos, ya que ocupan
grandes cantidades de memoria.
Además, el desarrollo del hipertexto, al
permitir la conectividad entre las referencias y los documentos fuente a través
de los enlaces, ha roto también las fronteras entre documentos primarios y
documentos secundarios, aunando en un mismo espacio datos referenciales y acceso
directo al documento fuente.
Hasta épocas recientes, las bases de datos eran
productos comerciales desarrollados y mantenidos por ciertas empresas que las
comercializaban bien en formato CD-ROM o bien
las distribuían para su consulta, previo pago, en línea vía
telnet. La mayoría eran bases de datos
bibliográficas o de legislación. Las organizaciones
también contaban con sus propias bases de datos construidas sobre los sistemas
de gestión más conocidos para crear y mantener bases de datos como FileMaker,
Knosys,
Access, etc. Hoy todos estos programas se han visto obligados a ser
compatibles con la Web y a ofrecer la posibilidad de acceder, buscar y
recuperar los
datos en línea vía protocolo http. De esta forma, se han desarrollado y comercializado una serie de
herramientas y aplicaciones, comúnmente denominadas pasarelas web, que permiten
consultar las viejas -o nuevas- bases de datos creadas con estos sistemas de
gestión mediante el navegador web, pero
también, la existencia de estas herramientas ha favorecido el hecho de que cualquier persona
pueda hoy publicar su propia base de datos en su página web, para que pueda ser
consultada por cualquier usuario de la red. Estas pasarelas no son más que
herramientas de software que permiten la comunicación entre el
servidor web y la base de datos.
Así pues, la World Wide Web se ha convertido en sí
misma, en una interfaz de acceso a datos que puede ser utilizada por cualquier
usuario. Los nodos de un hipertexto no se limitan a incluir
texto, imagen o
sonido, sino también scripts y otros
elementos como APIs (Application Programming interface) o controladores
para conectividad de bases de datos e intercambio de
información tales como OLE (Open
Database Connectivity), CGI (Common
Gateway Interface), JDBC (Java Data Base Connectivity), SQL LINKS etc.
Todos estos objetos son los que hacen posible la existencia de elementos y
documentos dinámicos y los que aportan un verdadero dinamismo al hipertexto. Se
trata de componentes que deben ser diseñados en la interfaz de programación para
acceso a datos del hipertexto y que comprende tanto el diseño e interfaz de
Objetos de Acceso a Datos, como la interfaz de programación de aplicaciones.
De esta forma, se pueden construir bases de
datos utilizando aplicaciones y sistemas de gestión
de bases de datos como
Microsoft Access,
Oracle,
Sybase,
MySQL,
MSQL o
SQL Server, etc. y, por medio de una serie de herramientas de
acceso (CGI, DAO, ODBC, etc.) y desde entornos de desarrollo distintos, hacer
que estos datos sean accesibles vía Web para cualquier usuario que quiera hacer
una consulta en línea.
El acceso a los datos se puede realizar mediante distintas tecnologías Web,
entre las que destacan:
-
CGI: (Common Gateway
Interface o Interfaz de pasarela común)
http://hoohoo.ncsa.uiuc.edu/cgi/ es la
especificación de un protocolo que permite al servidor Web (HTTP) comunicarse con
programas o scripts externos. Los programas
CGI trabajan en el servidor Web y
pueden implementarse utilizando diferentes lenguajes de programación (COBOL,
C, Perl, etc.). Para que el usuario recupere un documento dinámico HTML a
través de CGI, generalmente se sigue la siguiente secuencia básica:
-
El usuario cumplimenta los campos de un formulario HTML
y pulsa el botón de envío. Antes de proceder al mismo, el
navegador
determina el método HTTP para el envío, identifica los campos del
formulario, construye el conjunto de datos como pares: nombre del
control / valor asociado y codifica el conjunto de datos.
-
El navegador realiza una solicitud HTTP al
servidor Web, enviando el conjunto de datos del formulario para que sea
procesado por el programa especificado en el atributo del formulario action.
-
El servidor recibe la solicitud y a partir de ella
determina que se le está pidiendo la activación de un programa CGI. Se
lanza un nuevo proceso CGI que recibe la información necesaria para su
ejecución.
-
El programa CGI se ejecuta procesando la
información y devolviendo el resultado al servidor Web.
-
El servidor recibe el resultado de proceso CGI y
prepara una respuesta HTTP válida (anexando alguna cabecera) que se
le envía al cliente.
-
El navegador muestra el resultado recibido que contendrá
información dependiente de lo que el usuario introdujo en el formulario HTML.
-
ASP: Microsoft ha desarrollado
sus propias aplicaciones y servidores. Las primeras soluciones se basaban en
el servidor Web ISS (Internet Information Server), el lenguaje de script
ASP (Active Server Pages) y la tecnología de objetos distribuidos COM (Componente Object Model). ASP proporciona
acceso a datos apoyándose en los objetos ADO (ActiveX Data Objects) y
ODBC. El uso de la interfaz ODBC le permite a ASP trabajar sobre cualquier
sistema gestor de bases de datos que proporcione un controlador o driver (MySQL,
SQL Server,
Oracle,
Informix, etc.). Los objetos ADO, basados en la tecnología COM (Component
Object Model), ofrecen métodos que encapsulan el acceso a datos para su
utilización en páginas ASP (Connection, RecordSet, Command, etc.). Se puede utilizar ASP sobre un
IIS (Internet Information Server)
ejecutándose en Windows NT Server 4.0. Se necesita dar de alta un DSN (Data Source Name) que asocia el SGBD (MySQL), el nombre de la fuente de datos y un driver ODBC para
MySQL.
http://www.asp.net/
-
.NET es la última
aplicación desarrollada por Microsoft e incluye ASP+, C#, mientras deja de lado las anteriores
inversiones de Microsoft en Java (y programas relacionados como Microsoft
Visual J++). Todas estas soluciones se basan en estándares propietarios,
aunque en la plataforma .NET se incluye
soporte a SOAP.
-
JSP: El acceso a base de datos desde
JSP (Java
Server Pages), al
igual que desde Servlets, se apoya en la tecnología JDBC de Java. Para ello se
precisa un controlador o driver que proporcione el acceso a
la base de datos subyacente (MySQL).
JSP es un lenguaje muy potente de código abierto que permite crear de manera
fácil aplicaciones Web. J2EE (Java 2 Enterprise Edition)
es una tecnología de las más utilizadas. A veces se utiliza el
término: servidores de aplicaciones Java para referirse a aquellos
servidores de aplicaciones que implementan de forma adecuada las soluciones
propuestas por J2EE. J2EE es una especificación que propone un estándar para
servidores de aplicaciones. Define diferentes tecnologías e indica cómo deben
trabajar juntas. Todos los servidores de aplicaciones J2EE deben pasar un test de
compatibilidad, que garantiza la correcta implementación de las tecnologías
Java. Muchos grandes fabricantes como IBM, Sun Microsystems, Hewlett-Packard,
Oracle,
Sybase, etc. utilizan J2EE. Sin embargo, Java consume una gran
cantidad de recursos y la máquina virtual Java es lenta.
http://java.sun.com/products/jsp/
-
PHP:
PHP o Hypertext
Preprocessor ofrece
interfaces propias de acceso a multitud de fuentes de datos: BBDDs (MySQL,
mSQL,
Oracle 8, etc.), servidores de directorio (LDAP), texto en XML, etc.
Todas ellas están documentadas en la página Web de PHP:
http://www.php.net/.
Diseñar hoy una web
se ha convertido en una labor compleja puesto que se exigen conocimientos de
arquitectura de la información en sus
distintas facetas y una de ellas, es administrar y gestionar bases de datos. La
Web es aquí entendida como interfaz de software que permite una serie de
funcionalidades como que el usuario pueda interrogar y consultar de forma
directa a la base de datos y obtener las referencias o el acceso directo a los
recursos o documentos buscados.
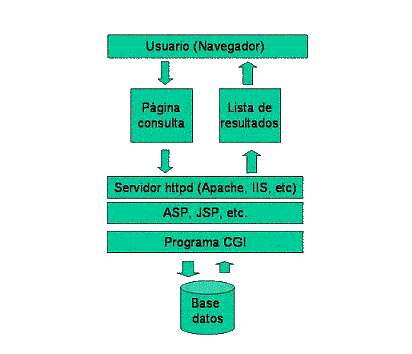
Fuente: Ernest Abadal. Esquema de funcionamiento.
Bases de datos documentales en el web: análisis del software para su
publicación.
http://www.hipertext.net/web/pag255.htm
Los SGBD suelen
incluir herramientas de administración que permiten ajustar el rendimiento en
función de las necesidades particulares. Muchas empresas cuentan son sus propios
administradores de bases de datos, pero también hay muchas otras que no, y lo
más probable es que el diseñador web tenga que administrar también las
bases de datos. Sin embargo, la complejidad del diseño ha dado lugar al
nacimiento de nuevas profesiones que se encargan de llevar a cabo procesos tales
como el análisis o minería de datos (data mining) o la distribución de los
mismos (data warehouse).
Como se ha afirmado anteriormente, existen sistemas de gestión de bases de datos tanto de
uso libre, como soluciones comerciales de pago. Una de las tendencias más claras en
la Web actual es integrar el acceso a datos en los servidores de
aplicaciones y esto ha conducido a que casi todos los
fabricantes de sistemas de gestión de bases de datos comerciales
ofrezcan sus propios servidores de aplicaciones que se integran a bajo nivel con
los productos de bases de datos de la misma empresa. Como ejemplos, tenemos Sybase
Enterprise Server y Oracle Application Server. Un servidor de aplicaciones
no es más que un cambio de nombre para algunos servidores Web de nueva
generación que permiten construir aplicaciones. Suelen asociarse con servidores
de alto rendimiento pensados para dar servicio a sitios Web con grandes necesidades
para gestionar movimientos de datos, afluencia de visitas, atención de transacciones hacia bases de datos, etc. Generalmente los
fabricantes del sector tienen a disposición del público un servidor Web básico y
otro con multitud de extensiones integradas al que llaman servidor
de aplicaciones.
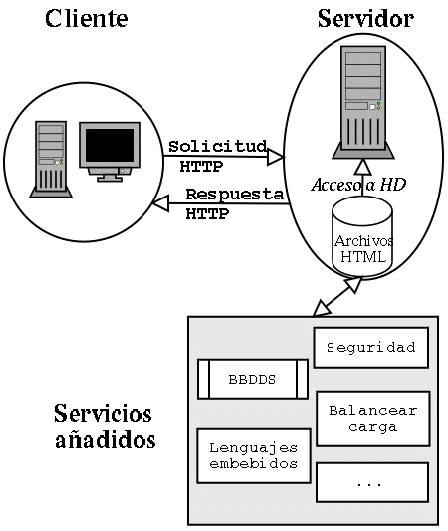
Fuente: LÓPEZ FRANCO, José Manuel.
Arquitectura de funcionamiento de un servidor de aplicaciones.
http://trevinca.ei.uvigo.es/~txapi/espanol/proyecto/superior/memoria/node21.html#serv:aplicaciones
Un servidor de aplicaciones clásico se apoya en un modelo
cliente/servidor de tres capas:
- Presentación: una interfaz, generalmente gráfica que reside en los
clientes. El ejemplo típico es un navegador.
- Lógica de negocio: donde reside el servidor de aplicaciones y el
conjunto de programas a los que da soporte.
- Almacenamiento: generalmente una base de datos.
Los servicios añadidos a los servidores de aplicaciones suelen ser:
generación de código HTML ó XML, trabajo con bases de datos y gestión de
transacciones, funcionamiento multiproceso para atender a distintas peticiones,
establecimiento de distintas sesiones para acceso de usuarios, mecanismos de
seguridad y autentificación, monitorización para evitar fallos, etc.
No es fácil saber cuántos servidores hay en Internet, pero existen empresas
consultoras independientes que se dedican a medir su evolución como
http://www.netcraft.com
Los servidores más utilizados son: Apache, Microsoft IIS, iPlanet de
Netscape, Zeus, thttpd, Rapidsite, etc. Un listado muy completo de servidores de
aplicaciones puede encontrarse en:
http://www.serverwatch.com/appservers.html
De cualquier forma, hay que tener en cuenta que, aparte de
cómo se almacenan los datos en la base de datos, una cuestión importante es la
interfaz de presentación de esos datos. Las interfaces o presentaciones de una
aplicación hacia el usuario han ido evolucionando a través del tiempo y,
actualmente se utilizan muchos lenguajes visuales denominados de cuarta
generación como son: Visual Fox Pro, Visual Basic, Delphi, etc. También los ambientes Web,
se han vuelto una opción viable para las aplicaciones distribuidas en Internet y esto se ha logrado
mediante el uso de ciertas herramientas como son: HTML,
DHTML y JavaScripts.
Con tecnologías como el scripting y
DHTML, los desarrolladores
de aplicaciones pueden crear acciones con interfaces de Web funcionales, basadas
para la entrada de datos o salida de resultados de búsqueda sin usar controles comunes o
applets. La tendencia es que las empresas intenten mejorar la
interfaz hacia el usuario para que éste tenga la
oportunidad de explotar la mayor cantidad de información, en una única
pantalla o ventana del sistema.
Las interfaces de programación denotan el proceso de acceso y manipulación
de los datos a una base de datos, partiendo de la aplicación. El siguiente
esquema muestra 4 niveles o interfaces:

Interfaces de Programación para el acceso a datos.
La primera interfaz corresponde a la de Aplicación, la cual abarca y/o
corresponde a cada uno de los programas clientes.
La Interfaz de Objetos de Acceso a Datos, se encuentra como punto medio
entre las aplicaciones y las API's que llegan a ser necesarias para el acceso a
las bases de datos. Entre las tecnologías que pertenecen a la
Interfaz de Objetos de Acceso de Datos encontramos: DAO (Data Access Objects), ADO (ActiveX
Data Objects), RDO (Remote Data Object), RDS (Remote Data Service) y MIDAS (Middle-tier
Distributed Application Service). Su función es encapsular los componentes que se encuentran en la interfaz que corresponde a la
de API's, con la finalidad de reducir el desarrollo de la aplicación y los
costos de mantenimiento y deben situarse en todos los equipos que ejecuten la
aplicación, ya que se encuentran casi de manera conjunta con la aplicación.
Por su parte, la Interfaz de Programación de Aplicaciones (Application Programming
Interface, API), se encarga de mantener el diálogo con la base de datos, para
poder llevar a cabo el acceso y manipulación de los datos. Algunos de los
componentes que forman parte de esta interfaz son los siguientes: OLE DB, ODBC (Open
Database Connectivity), JDBC (Java Data Base Connectivity), ISAPI (Internet
Server Application Programming Interface) y CGI (Common Gateway Interface).
La función que tienen las API's, es la de ser una interfaz entre las
aplicaciones y las bases de datos, llevando ésta tarea unas veces a través
de los clientes y otros a través del servidor de base de datos. Esto quiere decir, que
puede darse el caso de que el cliente conste de las tres primeras interfaces o
niveles, o que se encuentren las dos últimas en el servidor. La interfaz correspondiente a la base de datos, es donde se
encontrará el servidor y toda la información depositada en él.
Para poder accesar y manipular la información de una base de datos, es
necesario llevar a cabo la instalación de ciertos API's o controladores, que son
indispensables para efectuar la conectividad de los datos externos, y
vincularlos a la aplicación para su correcta y adecuada utilización.
Las API's que se describen a continuación, son un claro ejemplo del
proceso correspondiente a la conectividad de datos.
-
ODBC (Open Data Base
Connectivity): Esta tecnología proporciona una interfaz común para tener acceso a bases
de datos SQL heterogéneas. ODBC está basado en SQL (Structured Query Language)
como un estándar para tener acceso a datos. ODBC permite la conexión fácil desde
varios lenguajes de programación y se utiliza mucho en el entorno Windows. Sobre
ODBD Microsoft ha construido sus extensiones OLE DB y ADO. Los OCBD se
pueden clasificar en 3 categorías:
- Los ODBC's que permitan la realización de consultas y actualizaciones.
- Los ODBC's que mediante ellos se pueda llegar a la creación de tablas en
la base de datos.
- Los ODBC's propios de los DBMS, los cuales se pueden llegar a manipular
ciertas herramientas de administración.
-
CGI (Common
Gateway Interface): es una de las soluciones que se está
utilizando más para la creación de interfaces Web/DBMS. Entre las ventajas de la programación CGI,
destaca la sencillez, ya que es muy fácil de entender, además de ser un lenguaje
de programación independiente, ya que los escritos CGI pueden elaborarse en
varios lenguajes. También es un estándar para usarse en todos los servidores
Web, y funcionar bajo una arquitectura independiente, ya que ha sido creado para
trabajar con cualquier arquitectura de servidor Web. Como la aplicación CGI se encuentra funcionando de forma independiente,
no pone en peligro al servidor, en cuanto al cumplimiento de todas las tareas
que éste se encuentre realizando, o al acceso del estado interno del mismo. Pero
el CGI presenta cierta desventaja en su eficiencia, debido al que el servidor
Web tiene que cargar el programa CGI y conectar y desconectar con la base de
datos cada vez que se recibe una requisición. Además, no existe un registro del
estado del servidor, sino que todo hay que hacerlo manualmente.
-
ISAPI (Internet Server
Application Programming Interface): Es la interfaz propuesta por Microsoft como una alternativa más rápida
que el CGI, y está incluida en el Servidor Microsoft Internet Information (IIS). Así como los escritos CGI, los programas escritos usando ISAPI habilitan
un usuario remoto para ejecutar un programa, busca información dentro de una
base de datos, o intercambia información como otro software localizado en el
servidor. Los programas escritos usando la interfaz ISAPI son compilados como
bibliotecas de enlace dinámico (DLL - Dinamic Link Library), ya que son cargados
por el servidor Web cuando éste se inicia. Dichos programas se vuelven
residentes en memoria, por lo que se ejecutan mucho más rápido que las
aplicaciones CGI, debido a que requieren menos tiempo de uso de CPU al no
iniciar procesos separados. Uno de los programas ISAPI más usados es el HTTPODBC.DLL que se usa para
enviar y/o devolver información hacia y desde las bases de datos, a través de
ODBC. Además, ISAPI permite realizar un procesamiento previo de la solicitud y
uno posterior de la respuesta, con lo cual manipula la solicitud/respuesta HTTP.
Los filtros ISAPI pueden utilizarse para aplicaciones tales como autenticación,
acceso o apertura de sesión.
-
NSPAI. es la API propuesta por
Netscape para extender la funcionalidad de sus servidores.
-
DBI (PERL): Perl es uno de los
lenguajes más utilizados para programación en la Web y proporciona su propia interfaz
de acceso a datos, llamada DBI
(DataBase Interface).
Es especialmente utilizado bajo plataformas Linux/Unix,
solucionando las complejidades de ODBC en estos sistemas. DBI
actúa como una abstracción para un conjunto de módulos
DBD
(DataBase Driver).
Cada módulo DBD
actúa como manejador de un sistema gestor de base de datos distinto. Existen
módulos para prácticamente cualquier SGBD
(Oracle,
Informix,
MySQL,
etc.) y puentes hacia otras tecnologías como ADO, JDBC
...
-
JDBC (Java Data Base Connectivity):
se trata del estándar para la conectividad entre el lenguaje Java y un amplio
rango de sistemas gestores de bases de datos. Los JDBC pueden desenvolverse
tanto en un nivel cliente, esto es, trabajando del lado de la aplicación, o en
el servidor directamente relacionado con la base de datos. Cuando se encuentre a
nivel cliente, trabajará con la tecnología ODBC para acceso a los datos. Hay
diversos tipos de controladores JDBC:
-
El puente JDBC-OBDC:
fue uno de los primeros controladores disponibles, implementa un enlace para
utilizar un controlador ODBC desde Java. Con el tiempo han surgido
controladores JDBC
específicos para cada base de datos que mejoran el rendimiento del puente JDBC-ODBC.
-
Controladores Java parcialmente
nativos: usan tanto código Java como binario específico de cada plataforma.
-
Controladores JDBC-Net
de Java puro: son controladores escritos completamente en Java que entienden
un protocolo de red estándar (HTTP,
etc.) y permiten comunicarse con un servidor de acceso a bases de datos, que
es el que finalmente provee el acceso al SGBD
específico (posiblemente con ODBC).
-
Controladores de protocolo
nativo en Java puro: escritos en Java puro, utilizan el protocolo específico
de la marca del SGBD.
-
SQL LINKS: se trata de
controladores que se encargan de realizar la comunicación remota entre la
aplicación y los servidores remotos de bases de datos, permitiendo una
comunicación casi directa y muy rápida. Los ha desarrollado la empresa Inprise
y permiten conexiones con otros servidores de bases de datos como Interase,
Oracle,
Sybase,
Informix,
Microsoft
SQL Server, etc.
Las 2 tecnologías más importantes de
conectividad a la la base de datos son ADO y JDBC.
ADO:
Existen varios niveles o interfaces para lograr la
comunicación o acceso a la base de datos a través de la aplicación. El siguiente
esquema muestra 2 de los principales niveles, dentro de los cuales se encuentra
ADO.
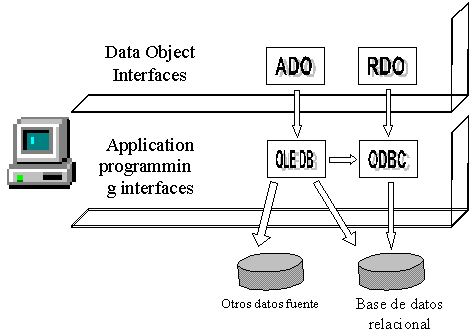
Fuente: Taller de Base de Datos.
http://www.itver.edu.mx/comunidad/material/tallerbd/apuntes/index.html
Por lo general, las interfaces de objetos de datos son más
fáciles de usar que las APIS, aunque las APIs ofrecen más funcionalidades. ADO (ActiveX
Data Objects) es la interfaz de objetos de datos para OLE DB, y RDO (Remote Data Objects) es la interfaz para el objeto ODBC.
ADO encapsula el API OLE DB en un modelo objeto simple que
reduce el desarrollo, mantenimiento y costo de la aplicación. Es muy fácil de
usar, utiliza lenguajes de programación como Visual Basic, Java, C++, VBScript y
JScript, puede accesar datos desde cualquier recurso OLE DB y además, es
extensible. Es la interfaz utilizada por Microsoft.
El modelo ADO, basado en el modelo de objetos, define una jerarquía de objetos programables que pueden ser
usados por desarrolladores de páginas Web para acceder a la información almacenada
en una base de datos. Una jerarquía es un grupo de objetos relacionados que
trabajan juntos para un mismo propósito. Por ejemplo, en la siguiente figura, cada
caja representa un objeto, y cada línea representa una asociación directa entre
ellos.
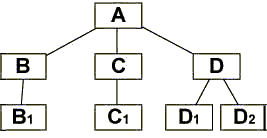
ADO está compuesto de siete objetos, algunos de alto nivel
como Connection, Command y
Recordset, que pueden ser creados y eliminados por el
usuario y otros con distintas funcionalidades como designar propiedades de
conexión, definir sentencias y ejecutarlas, optimización de consultas, etc.
Estos elementos se representan
en la siguiente figura:
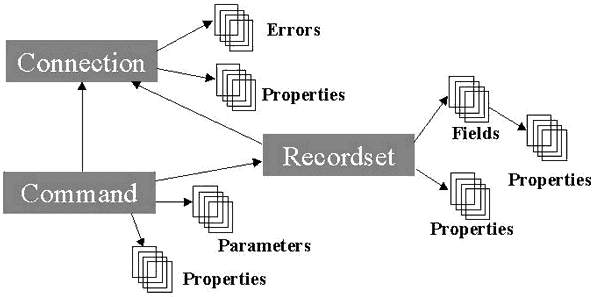
Fuente: Taller de Base de Datos.
http://www.itver.edu.mx/comunidad/material/tallerbd/apuntes/index.html
Cada uno de los objetos anteriores contiene una colección
de objetos Property. El objeto Property permite a ADO mostrar dinámicamente las
capacidades de un objeto específico.
ADO permite diseñar sitios web que pueden acceder
repetidamente a la misma base de datos usando una misma búsqueda u otra
similar. Se pueden compartir conexiones y esto significa una menor carga de trabajo
para el
servidor de la base de datos, un tiempo de respuesta más rápida y más accesos a
página con éxito.
Existe un componente llamado RDS (Remote Data Service)
que ofrece el ambiente de Acceso
Universal a Datos, ya sea desde Internet o la World Wide Web, creando un marco
de trabajo
que permite una interacción fácil y eficiente con los datos fuente OLE DB tanto
en
Intranets corporativas o en Internet. RDS ofrece la ventaja de obtener por el
lado del cliente resultados de datos, actualización y soporte para controles ADO
y ofrece el modelo de programación OLE DB/ADO para manipular datos de las
aplicaciones del cliente.
JDBC
JDBC o Java Data Base Connectivity, creado por la
empresa Sun, es la API estándar de acceso a bases de datos con Java. Sun optó
por crear una nueva API en lugar de utilizar ODBC, porque esta última presentaba
algunos problemas desde ciertas aplicaciones
Java. ODBC es una interfaz escrita en lenguaje C, que al no ser un lenguaje portable,
hacía que las aplicaciones Java también perdiesen la portabilidad. Además, ODBC
ha de instalarse manualmente en cada
máquina, mientras que los controladores (drivers) JDBC que están escritos en Java son
automáticamente instalables y portables. El nivel de abstracción al que trabaja JDBC es
más alto que el de ODBC y, de esta forma, se pueden crear librerías de más alto
nivel,
Para trabajar con JDBC es necesario tener controladores que
permitan acceder a las distintas bases de datos. Sin embargo, ODBC sigue siendo
hoy en día la API más popular para acceso a
Bases de Datos, por lo que: Sun se ha visto obligada a diseñar un puente que
permite utilizar la API de JDBC en combinación con controladores ODBC.
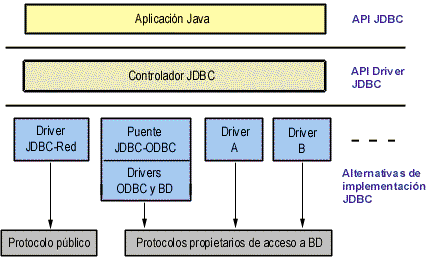
Fuente: Taller de Base de Datos.
http://www.itver.edu.mx/comunidad/material/tallerbd/apuntes/index.html
Las tecnologías que se emplea para la conectividad entre los datos y la
aplicación, se ha convertido en un factor muy importante a la hora de
desarrollar un proyecto web que cuente con funcionalidad de acceso a datos. A continuación se muestra un cuadro comparativo
de las dos tecnologías más importantes en este sentido: ActiveX Data Objects (ADO) y Java Data Base Connectivity (JDBC).
|
ADO
|
JDBC
|
-
Tecnología elaborada por Microsoft
-
Tiene la principal función de realizar la solicitud de los datos a la
base de datos.
-
Esta solicitud la realizará mediante la tecnología OLE DB, la cual
estará en contacto de manera directa con la base de datos.
-
La tecnología OLE DB sólo se empleará cuando el DBMS pertenece de
igual manera a Microsoft, como es
SQL Server.
-
ADO encapsulará a ciertos objetos de OLE DB, para que de ésta manera
se realice la conexión con la base de datos.
-
Para realizar la gestión de acceso a bases de datos heterogéneas por
parte de ADO, éste hará uso de ciertos objetos de la tecnología RDO
(Remote Data Objects).
-
RDO dependerá de los ODBC’s para poder efectuar la conexión a la base
de datos y con esto el acceso a la información.
-
ADO podrá encontrarse trabajando en una página web en conjunto con
código HTML; esto será posible mediante un mecanismo de introducción de
instrucciones como es el VBscript.
-
Los objetos que conforman al ADO, no son compatibles con otros
lenguajes, solo por aquellos que pertenecen a la empresa Microsoft como
son: Visual C++, Visual Basic, Visual Java, etc.
|
-
Tecnología hecha por Sun Microsistems.
-
Tiene la función de ser un gestor para la aplicación con respecto a la
base de datos.
-
Por primera vez el JDBC fue empleado, tomando como intermediario entre
él y la base de datos al ODBC.
-
Como modelo cliente/servidor, el JDBC se encontrará trabajando en el
equipo cliente, conectándose directamente con la base de datos.
-
Como modelo de tres capas, el JDBC se encontrará en una capa
intermedia, donde todos los usuarios pasarán por él para poder accesar a
la base de datos.
-
Existen módulos JDBC que son propios de los fabricantes de DBMS, que
son utilizados para el rápido acceso a la información de las bases de
datos de los mismos.
-
JDBC no se encontrará ligado a trabajar con alguna tecnología en
específica, ya que se elaboró con la finalidad de ser portable.
-
En aplicaciones Web, JDBC se encontrará laborando en conjunto con
código HTML, mediante el mecanismo del Java script.
-
JDBC se elaboró con la finalidad de poder ser
compatible y portable para poder ser empleado en
aplicaciones y para la conexión con bases de datos.
|
Fuente: Taller de Base de Datos.
http://www.itver.edu.mx/comunidad/material/tallerbd/apuntes/index.html
Por último, hay que destacar también una tecnología llamada Web DB
utilizada por algunos servidores de bases de datos, con la cual, un usuario
puede solicitar la información que requiera y visualizarla a modo de respuesta
en una página Web, que será creada y elaborada por el propio servidor de base de
datos.
El proceso que comprende desde la solicitud a la
visualización de la información, puede ser representado de la siguiente manera:

En este esquema anterior destacan:
-
Navegador (browser): es la aplicación mediante la cual,
se tiene acceso libre a los servicios de Internet, y el medio que permite al usuario
introducir la solicitud para
visualizar la información, empleando el URL para especificar detalladamente el proceso
que se desea ejecutar.
-
Interfaz de Web: proporciona una interfaz para que un programa que se
ejecute en el servidor genere como salida el código HTML, en lugar de leer
simplemente un archivo estático de texto. Con ésta
interfaz se podrán crear las páginas Web de forma dinámica y/o utilizar la
implementación de formularios HTML. Esta interfaz permite tecnologías como
los CGI’s o aquellas otras que son propias del servidor de base de datos.
-
Agente PL/SQL: es el eslabón final del proceso entre un navegador
cliente y el servidor de base de datos. El agente ejecutará una llamada a un
procedimiento almacenado en el servidor. Este procedimiento creará una página HTML dinámica como salida, y el agente devolverá dicha salida al cliente a
través del navegador empleando de igual manera la Interfaz de Web.
-
Base de Datos (BD). En ella se mantendrá almacenada la información; se
encargará de proporcionar los datos que le hayan solicitado previamente, al
momento de la ejecución de un procedimiento por parte del Agente PL/SQL.
Esta herramienta es una muy buena opción para pequeñas o
medianas empresas, en las cuales llegaría a resultar muy costoso la
implementación de otro tipo de tecnologías más caras y avanzadas.
Bibliografía
 ABADAL, Ernest. "Diseño y creación de una
base de datos en un medio de comunicación". En: FUENTES, M. Eulalia (ed.).
Manual de Documentación
periodística. Madrid, Síntesis, 1995. ABADAL, Ernest. "Diseño y creación de una
base de datos en un medio de comunicación". En: FUENTES, M. Eulalia (ed.).
Manual de Documentación
periodística. Madrid, Síntesis, 1995.
 ABADAL, Ernest.
"Bases de datos documentales en el web: análisis
del software para su publicación". Hipertext.net, núm. 3, 2005.
http://www.hipertext.net/web/pag255.htm
ABADAL, Ernest.
"Bases de datos documentales en el web: análisis
del software para su publicación". Hipertext.net, núm. 3, 2005.
http://www.hipertext.net/web/pag255.htm
ABADAL, Ernest. CODINA, Lluís. Bases de datos documentales:
características, funciones y métodos. Madrid: Síntesis, 2005.
 AGUSTÍ I MELCHOR, Manuel. VALIENTE GONZÁLEZ, José Miguel. Bases de datos para
Multimedia:
Recuperación por Contenido. http://www.disca.upv.es/magustim/publicacions/docents/Intermedia2001/TEC_01.pdf
AGUSTÍ I MELCHOR, Manuel. VALIENTE GONZÁLEZ, José Miguel. Bases de datos para
Multimedia:
Recuperación por Contenido. http://www.disca.upv.es/magustim/publicacions/docents/Intermedia2001/TEC_01.pdf
CARIDAD, Mercedes. "Bases de datos documentales: el acceso a la
información". En: López Yepes, José (coord.).
Manual de información y documentación.
Madrid, Pirámide,1996.
CMS-Spain.com
http://www.ecm-spain.com/home.asp
CODINA,
Lluis. Bases de Datos Documentales: Talleres de Sistemas de Gestión de
Bases de Datos Documentales.
http://www.lluiscodina.com/metodos.htm#ii
CODINA, L. FUENTES, M. E. "Documentación periodística y bases
de datos: elementos para su fundamento como disciplina y propuesta de conjunto
nuclear de bases de datos". En: Fuentes, M. E. (dir.).
Anuari de biblioteconomía, documentació
e informació. Barcelona, COBDC, 1999.
DesarrolloWeb.com Desarrollo ASP a fondo.
http://www.desarrolloweb.com/asp/
DesarrolloWeb.com Manual sobre la plataforma .NET.
http://www.desarrolloweb.com/manuales/48/
DesarrolloWeb.com
Manual de PHP 5.
http://www.desarrolloweb.com/manuales/58/
DesarrolloWeb.com
Páginas dinámicas.
http://www.desarrolloweb.com/manuales/7/
DesarrolloWeb.com
Taller de MySQL.
http://www.desarrolloweb.com/manuales/34/
DesarrolloWeb.com
Tutorial de SQL.
http://www.desarrolloweb.com/manuales/9/
GARCÍA MORENO, M.ª Antonia.
"Pasado y presente de las bases de datos en línea. El caso español". Cuadernos de Documentación Multimedia, núm. 10, 2000.
http://www.ucm.es/info/multidoc/multidoc/revista/num10/paginas/pdfs/magmoreno.pdf
HORTH,
Henry F. SILBERCHATZ, Abraham.
Fundamentos de las bases de datos. McGraw Hill, 1998.
LÓPEZ
FRANCO, José Manuel. Integración de tecnologías a través de servidores
web.
http://trevinca.ei.uvigo.es/~txapi/espanol/proyecto/superior/memoria/memoria.html
LOPEZ
GUZMÁN, Clara. "Bases de Datos". En Modelo para el Desarrollo de
Bibliotecas Digitales Especializadas.
http://www.bibliodgsca.unam.mx/tesis/tes7cllg/sec_31.htm
LÓPEZ YEPES, Alfonso. "Bases de datos
documentales multimedia". En: López Yepes, José (coord.).
Manual de información y documentación.
Madrid, Pirámide, 1996.
LÓPEZ YEPES, José (coord.)
Manual de
Ciencias de la Documentación. Madrid, Pirámide, 2002.
MARTÍNEZ
SAN GERMÁN.
Taller de base de datos.
http://www.itver.edu.mx/comunidad/material/tallerbd/apuntes/index.html
PALMA, María del Valle. "Bases de datos y servicios de
información disponibles en Internet". En:
Documentación Digital
(CD-ROM). Barcelona: UPF, 1999.
PALMA, María del Valle.
"Técnicas y métodos para mejorar la calidad de la indización y su recuperación
en bases de datos documentales de ciencias sociales y humanidades".
5es Jornades Catalanes de Documentació: biblioteques, centres de documentació i
serveis d’informació. Barcelona:
Cobdc; Socadi, 1995.
Programacion.net. ASP en castellano.
http://www.programacion.net/asp/
Programacion.net. Bases de datos en castellano.
http://www.programacion.net/bbdd/
Programacion.net. Java en castellano.http://www.programacion.net/java/
Programacion.net. PHP en castellano.
http://www.programacion.net/php/
TRAMULLAS, Jesús. "Sección
3:
Los sistemas de bases de datos y los SGBD”. En Introducción a la Documática.
http://tek.docunautica.com/ [Volver]
TRAMULLAS, Jesús. "Sección 6: Las bases de
datos multimedia". En Introducción a la Documática.
http://tek.docunautica.com/
RAZQUIN
ZAPE, Pedro. "Las bases de datos multimedia revisadas". Cuadernos de
Documentación Multimedia. Núm. 6-7, 1997-1998.
http://www.ucm.es/info/multidoc/multidoc/revista/cuad6-7/prazquin.htm
VALLE GASTAMINZA, Félix del. Diseño de Bases de datos.
http://www.ucm.es/info/multidoc/prof/fvalle/Disbd.htm

|




